
基础数据类型及变量
作用: 存储你在代码中数据,不同的类型有不同的存储形式以及范围
所有类型 :
sbyte、byte、int、short、long、byte、uint、ushort、ulong、float、double、decimal、bool、char、string
细分:
有符号整数存储最大数值存储的字节数sbyte-128 ~ 127 (3次2的平方)1 个字节(2的0次方)short-32768 ~ 32768 (4次2的平方)2 个字节(2的1次方)int约 -21亿 ~ 21亿 (5次2的平方)4 个字节(2的2次方)long-900万兆~900万兆(6次2的平方)8个字节 (2的3次方)无符号整数存储最大数值存储的字节数byte0 ~ 2551 个字节ushort0 ~ 655322 个字节uint0 ~ 42亿(大约)4 个字节ulong0 ~ 1800万兆(大约)8 个字节浮点型保留小数后多少为有效数字存储的字节数float7 / 8 位4 个字节double15 ~ 17 位8 个字节decimal (在小数后添加m字母)存储 27 ~ 28 位16 个字节特殊类型存储的内容存储的字节数booltrue / false1 个字节char单个字符 2 个字节string可变字符串根据字符串长度决定单位转换
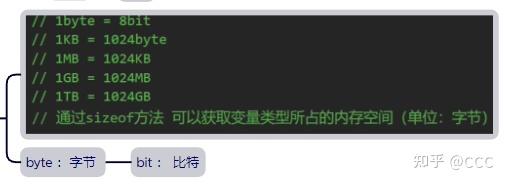
进制转换:
10转2:
将40转成2进制 -> 每步除于求余 -> 将所有的余数从后往前排则是对应的2进制数 -> 101000
2转10:
将101000转成10进制 -> 101000按2的对应位数方的和 (例如:个位数是0,第一个1的索引是5,第二个1的索引为3 == 2的5次方 + 2的3次方) -> 得出结果 40
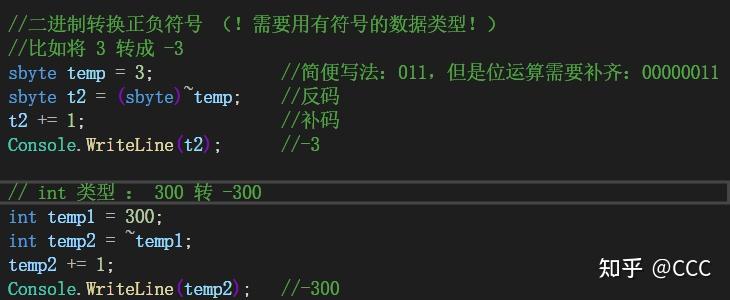
计算机二进制数转换正负 : 先反码后补码(取反+1)
十六或二进制数中:高八位为内存靠后的后8位,低八位则为靠前的前8位(左为高,右为低)
大小端:小端字节序(Little-Endian)和大端字节序(Big-Endian)是描述多字节数据在内存中存储顺序的两种不同方式,大端为人类习惯的从左到右书写,大端是符合人类常规思想处理数据的方式,小端则将其字节数据反过来,小端是符合计算机内部处理数据的方式,在数据传输时可能需要注意这个问题,C#默认为小端

大小端转换: 字节数组进行反转
转义字符
转义基础符号 :\ (在需要获得的字符前添加 \)
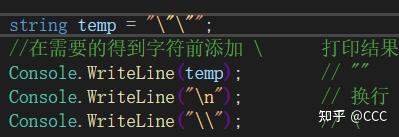
取消转移字符:@ (在字符串前添加@,直接取消任何转义字符)

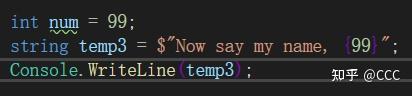
额外: 字符串内插 $ : (在字符串前添加$ ,在字符串里使用 { res } ,res是你需要传入的数据)
类型转换
分为显示转换和隐示转换、 需要注意是高精度数据类型转低精度数据类型会丢失部分数据
显式转换:
字符串转数值 : 类型.Parse (字符串) ,此方法需要注意是要转的类型必须是字串里对应的类型例如: “123.45”只能转浮点型,不能转整数型,否则会抛出异常
2. Convert.To :跟Parse类似,但会进行四舍五入,可以用于转ASCII(char字符)
例如:
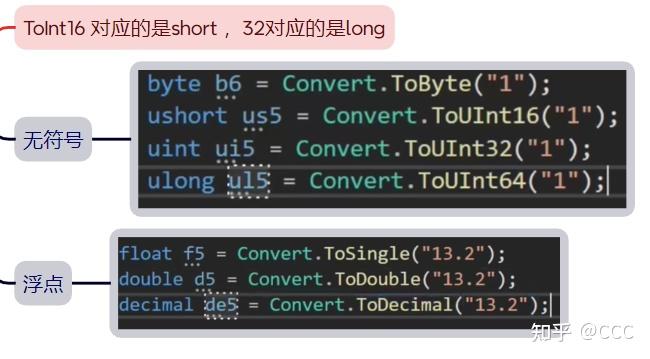
3. 其他类型转字符串 : 实例.Tostring()
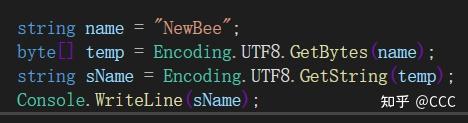
4. 用于通信或I / O:
byte[]数组和字符串互相转 : Encoding.UTF8.GetBytes("字符串")、Encoding.UTF8.GetString(byte[]);
例如:
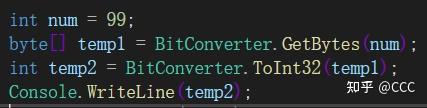
byte[]数组和其他类型互相转: BitConverter.GetBytes 、 BitConverter.To类型
例如:
隐示转换:
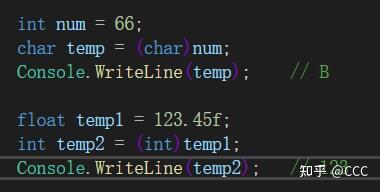
在实例前添加对应的类型,需要注意:
并不是所有类型都能通过隐式转换,比如string类型无法隐示转换。2. 高精度转低精度会丢失部分数值
另外一个作用可以通过char接收,打印出其对应的ASCII的对应字符
例如:
异常捕获

运算符
常用运算符类型:
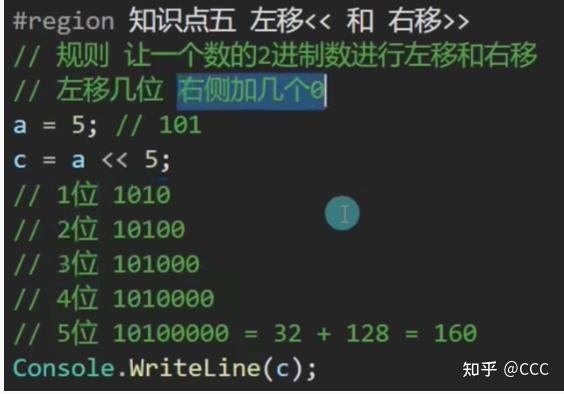
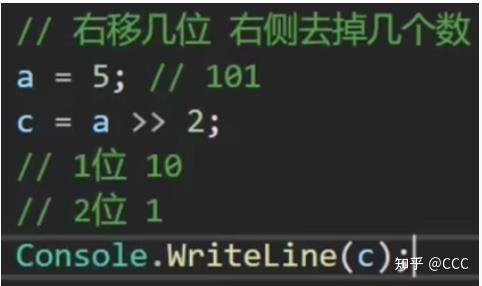
算术运算符关系运算符逻辑运算符位运算符* 和 /> 和 <!<<(左移) 和 >>(右移)- 和 +>= 和 <=&&| (位或) 和 & (位与)%== 和 !=||~ (位取反) 和 ^ (异或)需要注意的点:
1、在逻辑运算符中,优先级排序 : ! > && > ||
2、逻辑运算符的优先级 低于 算术运算符 和 条件运算符
3、逻辑运算符遵循短路原则
位运算符的相关计算:
技巧(用于二进制数运算):
1、(&)位与运算 : 有0则0 、( | )位或运算 : 有1则1、
(^) 异或运算: 相同为0 不同为1、(~)位取反运算: 0 变 1 , 1 变 0
2、二进制数基本特点:
按2进一位,则只有 0 、 1
一个快速记住常用二进制法则(8421): 01 = 1 、 10 = 2 、 100 = 4、 1000 = 8
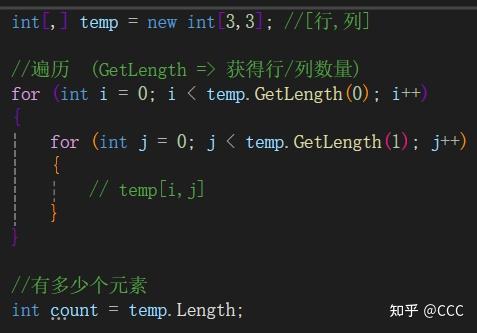
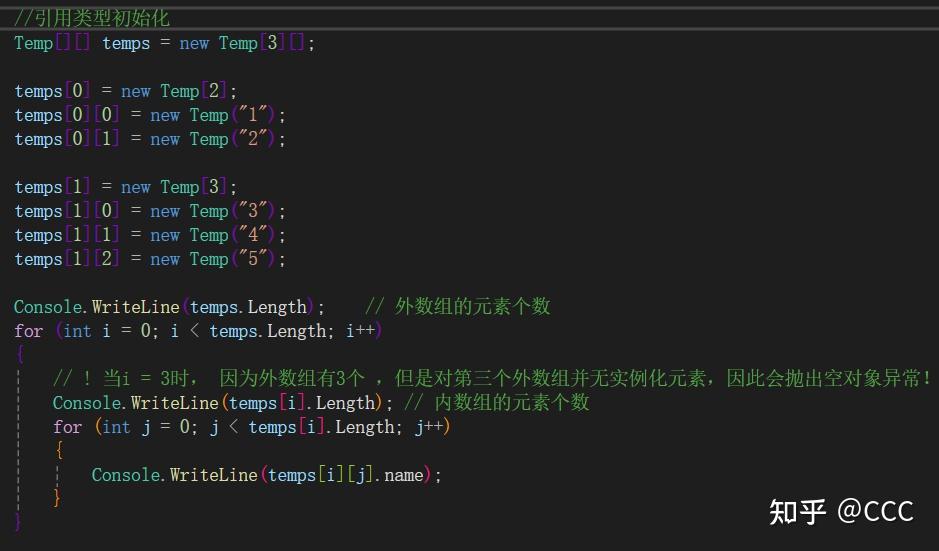
二维数组
常用于邻接矩阵、或者网格相关的场景
两种表现形式:
int[ , ]
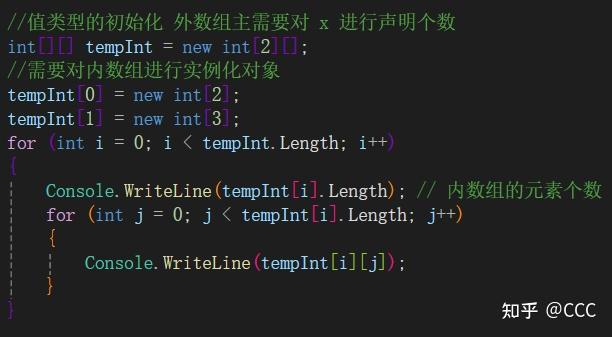
int[ ][ ] (交错数组)
其概念为: 用一个数组再包含另外一个数组(嵌套数组)
使用步骤:
1、对外数组进行初始化,每次初始化需要给当前数组进行实例化,(例如声明行的个数)
2、对内数组进行初始化,声明列的个数
值类型的相关使用(因为是值类型,所以不会抛出空对象指针,会返回默认值):
引用类型的相关使用(需要对每个引用类型元素进行实例化,不然会抛出空对象异常):

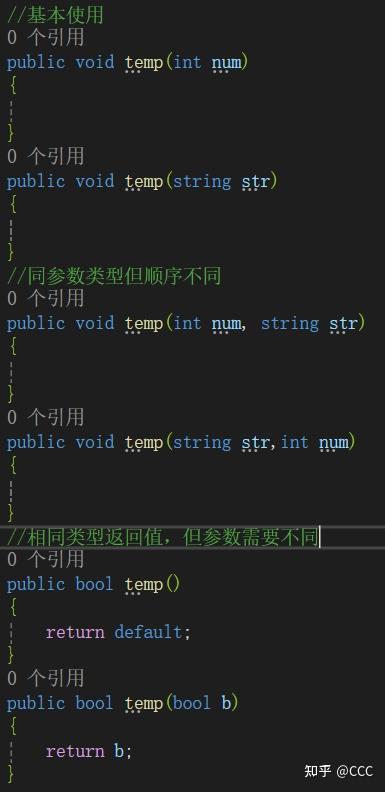
函数重载
概念:允许在同一作用域内声明多个同名函数,但这些函数的参数列表(即参数的类型、数量或顺序)必须不同
注意:可以相同类型返回值,但参数需要不同
值类型和引用类型
值类型:
值类型直接存储数据。当一个值类型的变量被赋值给另一个变量时,实际的数据会被复制。每个变量都有自己的副本,修改一个变量不会影响另一个变量
特点:

引用类型:
引用类型变量存储的是数据的地址(即引用)。它们指向堆中的数据,当一个引用类型的变量被赋值给另一个变量时,实际上是将引用(地址)复制过去,而不是数据本身。这样,两个变量就指向了同一个内存地址,修改其中一个变量会影响另一个变量
特点:

常见的值类型和引用类型:
引用类型:类、数组、string、委托、接口
值类型:除了引用类型外的类型基本都属于值类型
注意:
string虽然是引用类型,但是使用起来更多时候是值类型,string在实例化后就不再改变,如果后续需要改变,编译器会创建一个新的string并赋值给原来的string,因此频繁修改字符串内容可以改用StringBuilder以提高性能
内存管理与性能:
值类型:存储在栈上、创建和销毁效率较高,且栈的内存分配和释放速度较快。值类型通常用于存储小型的数据结构,例如数字、字符等
引用类型:
引用类型存储在堆上,内存分配相对较慢。它们更适用于需要较长生命周期和更复杂行为的数据结构。引用类型还需要垃圾回收器(GC)管理内存,因此可能会存在一定的性能开销
参考网址:
结构体
概念: 结构体(struct)是C#中一种数据类型,用来定义一个值类型的数据结构,通常包含多个字段(字段可以是不同类型的变量)。与类(class)不同,结构体是值类型,在赋值或传递给方法时,会复制结构体的所有数据,而类是引用类型,传递的是引用 (参考ChatGPT)
初始化声明:
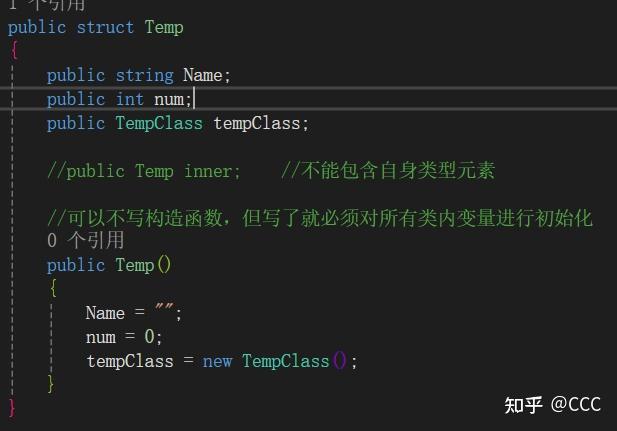
需要注意:
1、 结构体不能包含自身类型元素

2、可以不写构造函数,但写了就必须对所有类内变量进行初始化(语言版本较低)
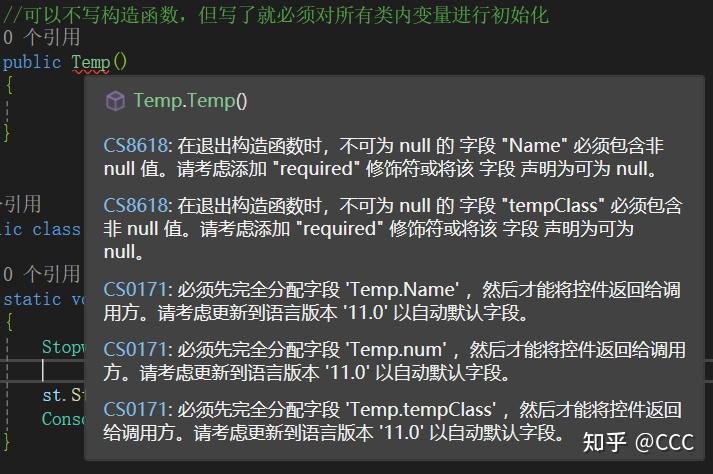
实例化:
声明可以不使用new实例化 ,但是使用其内部变量需要初始化值,声明有参也不会覆盖其无参构造

结构体特点及跟类的区别:
1、(继承)、访问权限只有private和public,因为结构体只能继承接口,不能继承结构体和类,而类都可以继承
2、(类型不同)、结构体没有析构函数,类有。因为结构体是值类型,而类是引用类型,因此结构体存储在栈上,而类存储在堆上
3、(无静态结构体)、没有静态结构体,但是可以有静态变量,而类都可以有
4、(值和引用类型的不同)、结构体是值类型,而类是引用类型,因此结构体对象赋值会进行深度拷贝(无论字段是引用还是值类型),但类进行对象赋值时,会分深浅拷贝
例如(对象赋值):
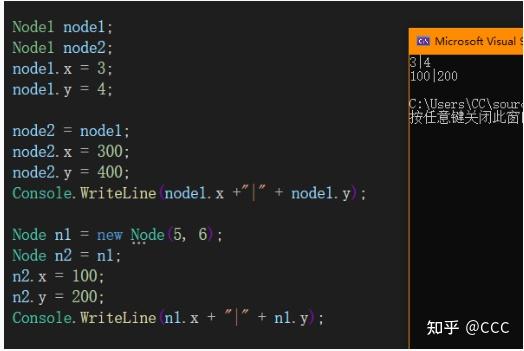
结构体:
在进行对象赋值,结构体修改新对象数值(值类型变量),原对象数值不会改变,但是修改引用类型会进行改变,因为值类型传递是值本身,引用类型传递是引用指针
类:
类改变新对象数值(无论是值类型还是引用类型)时,原对象也会发生改变,因此此时类所传递的是引用指针,而不是值本身
结构体和类的使用场景:
结构体通常适用于表示简单的值类型数据,例如点、矩形、颜色等。而类则更适合用于需要继承和复杂行为的情况
常量
两种表现形式: const 、 readonly
作用:不会改变的值
const:
特点
1、不可改变 2、声明时必须初始化值 3、全局共享(本质为静态成员)
readonly:
特点:
1、不可改变
2、在声明时可以先不初始化,后续在构造函数初始化 , 但是初始化后就不能在改变
3、readonly跟const最大区别就是readonly是实例字段,const为静态字段
规定: 一般采用全大写字母命名约定
基本用法:


枚举(enum)
概念:在 C# 中,枚举(enum)是一种值类型,用于定义一组命名的常数。枚举为一组相关的常量提供了更具描述性和可读性的名称,而不需要直接使用数字或其他值。这使得代码更加清晰、易读、易于维护
作用:描述某个数据和活动不同的状态
枚举的基本使用:
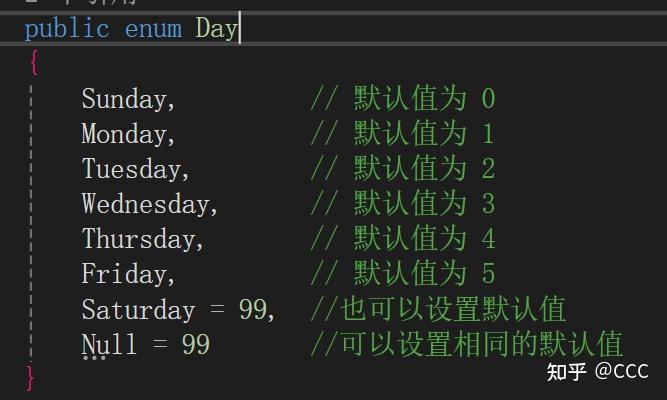

使用场景:
1、状态机
2、通过 Flags 特性使得枚举能够组合多个值
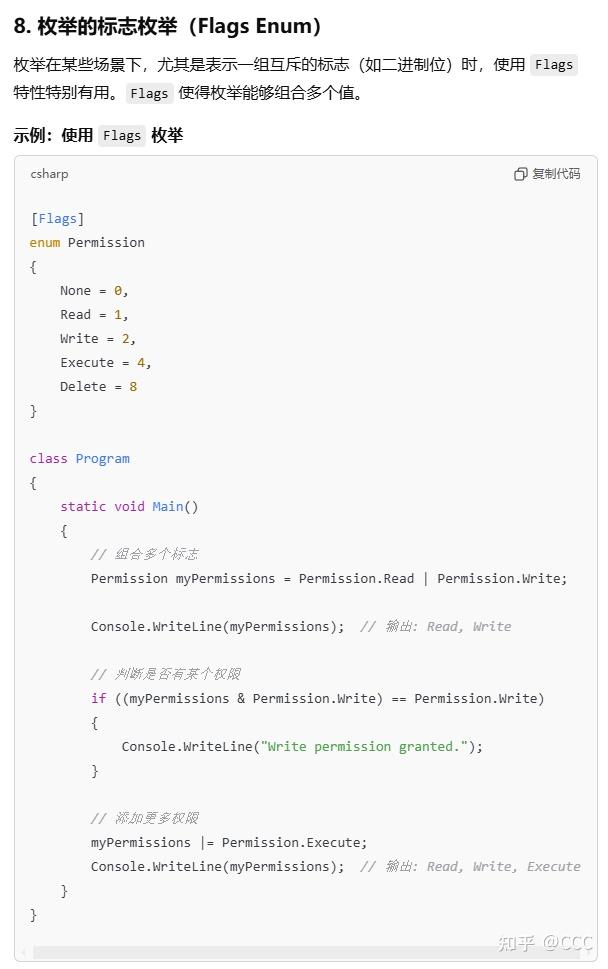
一些语法糖或技巧
变长参数(parmas):用于传入数组参数
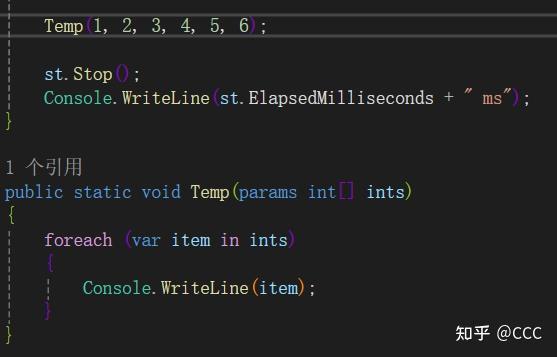
注意: parmas 必须作为最后一个参数传入
元组:用于将多个参数封装到一个参数进行传递
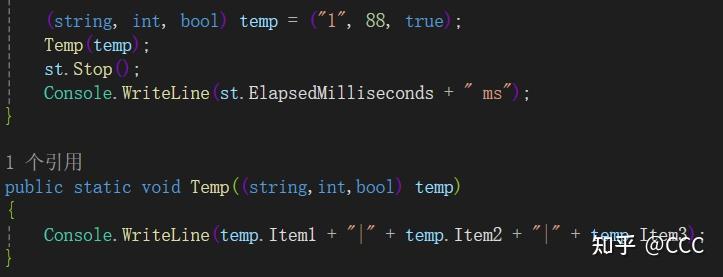
注意:Item表示传入的各个参数
作用:可以用在解决线程只能传入一个参数的问题,当然,也可以通过其他方法进行解决该问题,比如使用全局变量、委托等
计算机内存存储原理
计算机会将每一块内存(字节)分为不同编号,从而当需要创建时通过分配该地址,计算机会通过编号查找到该地址,计算机会将一部分内存分配给 操作系统,这部分内存计算机是无法自行调用的
比如:实例化一个引用类型步骤
1、先创建4个字节来接收引用的对象 Temp temp 存在堆中
2、在通过类中的元素来分配对应的内存空间 temp = new Temp ()
3、在分配空间的第一个内存为在栈中对象指向的地址(栈对象指向引用对象地址,栈存放该对象的地址)
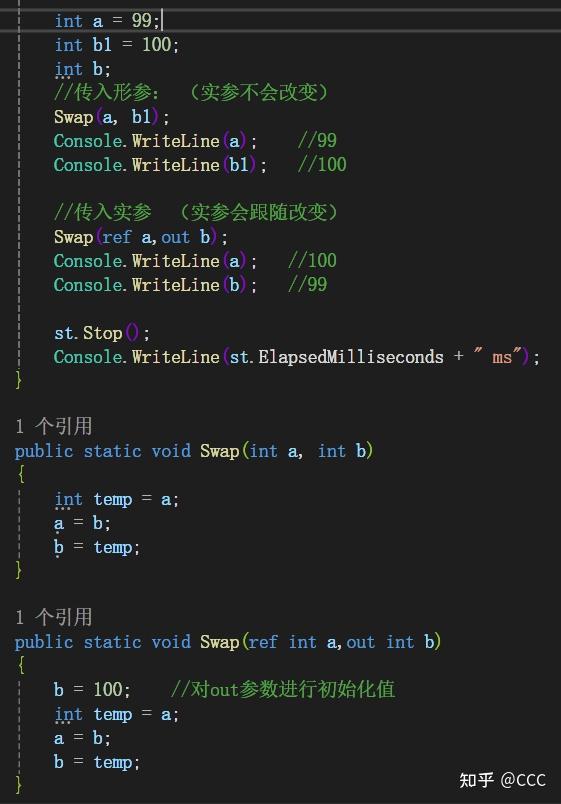
ref 和 out
概念:使用在方法传参,使用ref和out表示传入的是实参(指针),而非形参,因此使用ref 和out 传入的参数时,需要先初始化一个值
ref : 作为ref 参数传入到函数时,需要在传入前进行初始化才能使用
out:作为out 参数传入函数时,需要在传入后在函数体中进行初始化才能使用
注意:out在泛型委托和泛型接口时有另外一层含义:协变,与此对应的是 in 逆变
目标框架及其相关概念(学习中)
概念:C# 的目标框架(Target Framework)是指应用程序运行所依赖的特定平台和 .NET 库的集合。选择不同的目标框架,决定了程序可以运行在不同的环境中,例如 Windows、Linux、macOS、移动设备等
几种目标框架:
.Net Framework :Microsoft 初期开发的框架,主要用于 Windows系统,开发 Wnidows应用 和 Web服务开发,并不支持跨平台的运行及开发
.Net core :Microsoft 中期开发了新的目标框架为 .Net core,改善了 .Net Framework 不支持跨平台运行的缺点,支持 Windows、Linux 、Mac 等操作系统上运行,并且比 .Net Framework 更加高效,从1.x 更新到 3.x版本
.Net :现代版本且被Microsoft 推荐使用的目标框架,其特点免费、开源、跨平台,结合了.Net Framework和.Net core优点,并且包含了移动端的开发框架 Xamarin等其他应用的全新框架,形成单一的.Net平台,从 .Net 5.0 开始到目前最新的 .Net 9.0,还在持续更新
.Net Standard: 是一个由 Microsoft 提出的标准化 API 集合,旨在确保不同 .NET 实现之间的代码共享。它定义了一组 API,这些 API 在所有 .NET 平台(如 .NET Framework、.NET Core、Xamarin、Mono 等)中都有支持,从而使得开发者可以编写跨平台的类库,能够在多个 .NET 实现中共享

新版本能向旧版本进行兼容,简单来说就是它提供了一套统一基础且通用的接口方法给不同的.Net开发平台进行跨平台使用,如上述所提到的目标框架,有助于提高代码的重用性和可移植性,但在.Net 5.0出现后就形成了 .Net单一的平台,但是在Unity中仍然存在且提供使用
CLR (公共语言运行时): 是 .NET Framework 和 .NET Core 等 .NET 平台的核心组件之一。它是一个执行环境,负责管理程序的执行,包括内存管理、线程调度、异常处理、安全性、垃圾回收等。CLR 提供了许多功能,使得 .NET 应用程序能够高效、安全地运行
作用:负责将C#、http://VB.NET等高级语言编译成中间语言(IL),并在运行时将IL转换为机器码给计算机执行
好处:可以将不同的语言编译成相同的中间语言(IL),方便和计算机的交互
IL(中间语言):在 .NET 中,代码首先被编译为中间语言(IL),而不是直接编译为机器码。IL 是一种与平台无关的低级语言,可以在不同的操作系统和硬件平台上执行
C#编译器生成的是IL代码,并不是平台相关的指令,这一点适用于所有支持.NET的编译器
JIT(即时编译):CLR 包含一个即时编译器(JIT Compiler),它会将中间语言(IL)编译为特定平台的机器代码。JIT 编译器在运行时动态地编译代码,提供了平台特定的优化,Unity中的Lua脚本就是即时编译的
AOT(提前编译):是一个编译技术,它将源代码或中间代码(如 .NET 的 IL 代码)在程序运行之前进行编译,生成平台特定的机器码,将高级语言直接转成传统的编译型编程语言(如c/c++)。这与传统的 JIT(Just-In-Time)编译 相对,后者是将代码在运行时编译为机器码
元数据:元数据描述了每一个托管模块中定义的类型(如类、结构、枚举等)以及每个类型的成员(如字段、属性、方法、事件等)。且元数据总是与包含IL代码的文件关联,编译器同时生成元数据和IL代码,把两者绑定在一起并嵌入到最终生成的托管模块中,所以元数据和它描述的IL代码是同步的
托管代码:在 .NET 平台上编写的代码通常是托管代码,这意味着代码的执行由 CLR 管理,而不是直接由操作系统管理。CLR 负责运行时的内存管理、线程管理、异常处理等任务
非托管代码:非托管代码是直接与操作系统交互的代码,如 C 或 C++ 编写的应用程序。CLR 提供了与非托管代码互操作的功能(如 COM Interop 和 P/Invoke),使得 .NET 程序可以调用 C/C++ 编写的原生代码
Unity的跨平台方案 Mono/IL2CPP (!后期移到Unity相关知识!)
作用:允许开发者将游戏或应用程序从一个平台(如 Windows)部署到多个平台(如 Android、iOS、macOS、Linux、Web 等)
简单查找了一些相关资料:
1、好像在开发调试时选择Mono ,这有利于开发和维护,在发布项目时选择IL2CPP,有助于提高游戏的运行速度和对游戏空间大小的压缩
2、对于IOS平台来说,IL2CPP 是唯一支持 iOS 的方案,因为 iOS 对 JIT 编译有严格的限制。iOS 只能运行预编译的机器码,因此 IL2CPP 是发布到 iOS 的标准技术
3、Mono是JIT编译方法,而IL2CPP是AOT编译方式,编译耗时比JIT久,但是运行时比JIT快
之后是涉及一些相关Mono和IL2CPP发布后的游戏中,通过反编译文件来对Mono和IL2CPP的游戏源码进行提取,同时也可以提取到游戏的美术资源(AB包格式),这部分就留到Unity部分再展开,写在这是因为查资料时临时想起来的,怕我自己忘了总结,后期会进行移动
AssetStudio:https://github.com/Perfare/AssetStudio
dnSpy:https://github.com/dnSpy/dnSpy
Il2CppDumper:https://github.com/Perfare/Il2CppDumper
参考网址:
至此,C#的基础语法暂且先告一段落,后续如果还有更多内容会对其进行更新,如果有不对的地方还请各位斧正,感谢!
评论 (0)