
你是一个程序员, 老板要你做个游戏平台,支撑十多亿游戏用户数据的写入和存储。
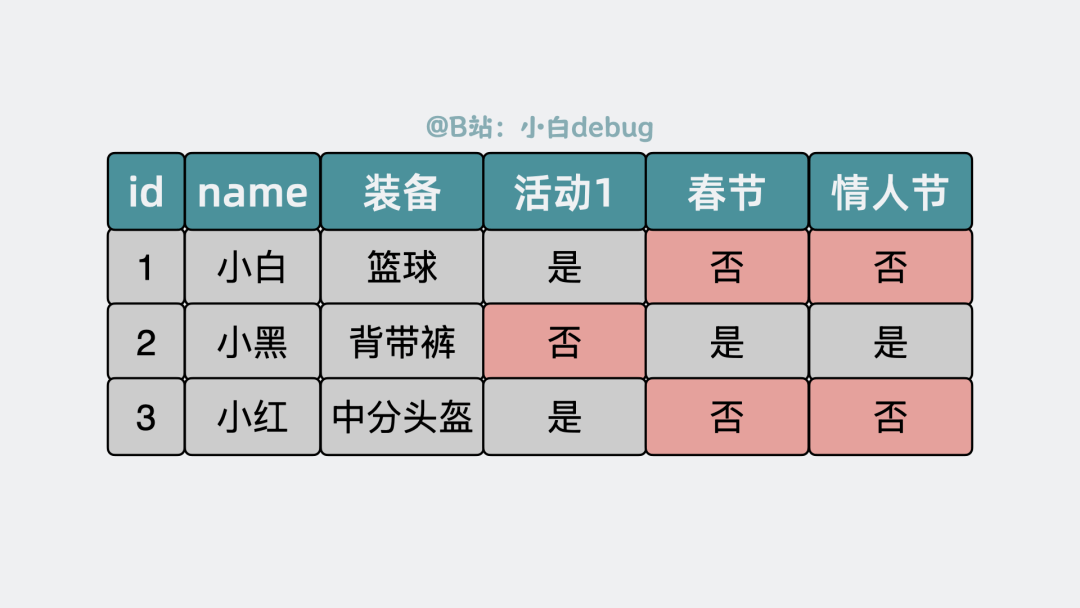
游戏用户包含多种字段,比如id, 装备、是否参与过节日活动等,功能不断迭代,需要支持扩展各种属性字段以及多维度查询。比如没参加过情人节活动的剑士有哪些?
那么问题就来了,你会选择使用什么,存储这么大量的游戏数据?
聊到存储,很容易想到可以使用MySQL数据库,将id、装备,活动等做成一个像excel的数据表。
为了支持多维度查询,我们需要为每个可能的属性都预留字段,甚至加上索引。比如预留春节、情人节活动等各种字段,但大多数角色并不会全部活动都参与,所以很多预留的字段都用不上,浪费空间。
很多预留的字段都用不上
而且游戏迭代频繁,每次增加活动时,都需要修改表结构,很麻烦。

每次增加活动都需要修改表结构
那么问题就来了,有没有一种既灵活又高效的存储方案?
有!没有什么是加一层中间层不能解决的,如果有,那就再加一层。
这次我们要加的中间层,是 MongoDB。
MongoDB是什么MongoDB是什么?
先说结论,MongoDB可以简单理解为,就是个"数据结构灵活点的Mysql"。

mongodb是数据结构灵活点的Mysql
Mysql的表是由多个行组成,每个行又由多个列组成。
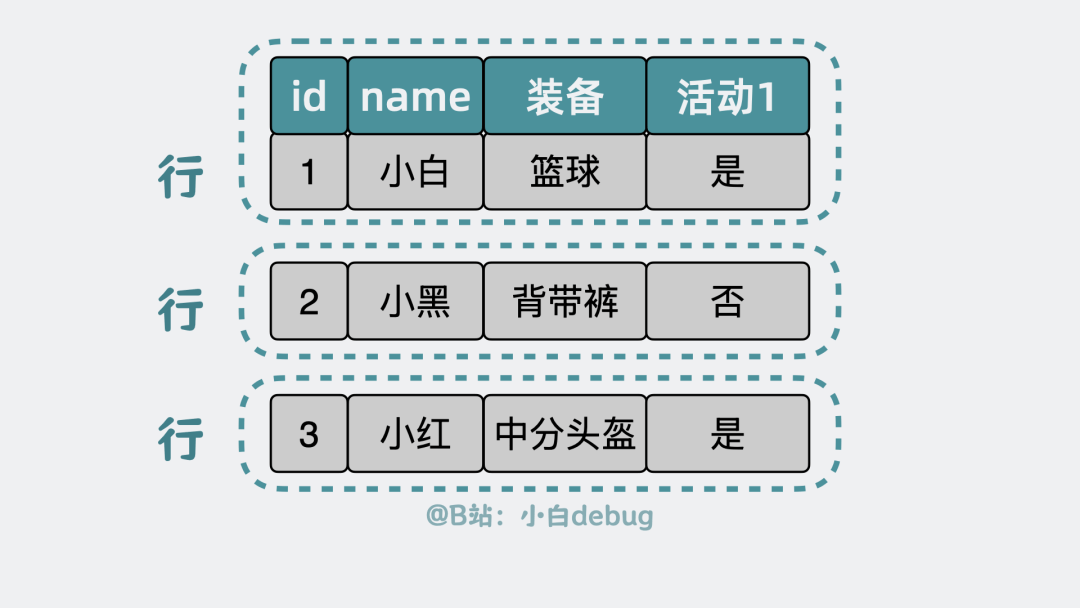
表由行组成
由于"列"这一概念的存在,导致了前面提到的表扩展和字段预留空间浪费的问题。
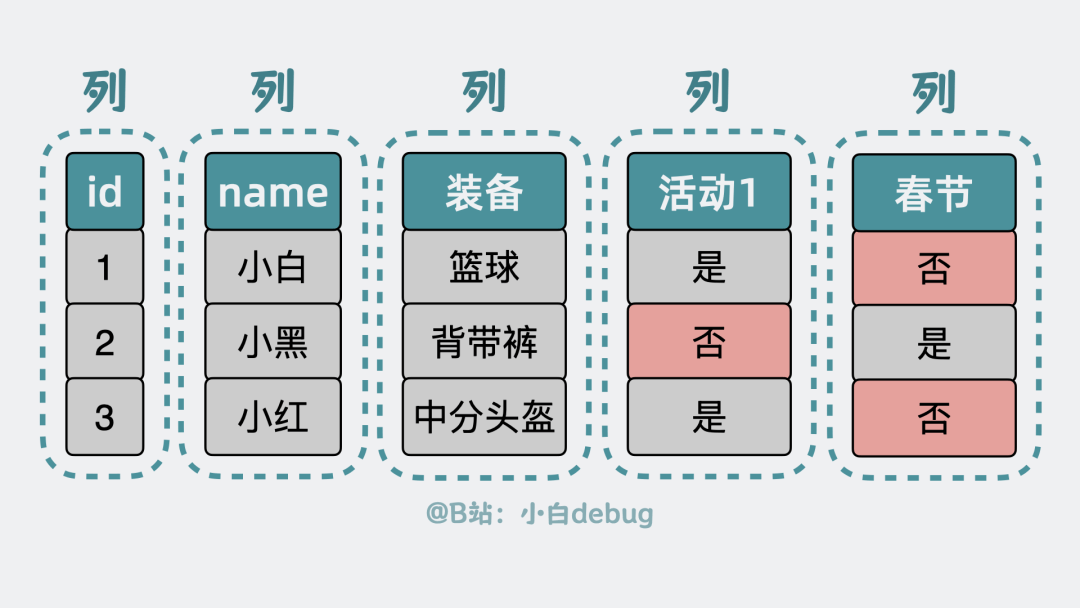
列的概念存在导致了问题
那我们索性抛弃列这个概念,将原来的多个列,聚合到一个长得像json的数据结构里,对于没用到的字段,不用预留,干脆就没有,我们管它叫文档, document,就像这样:

文档document
每个文档都有一个_id字段,也叫主键ID, 跟mysql表的主键ID是一个意思,用来唯一定位数据。

主键ID
文档内部想加什么字段就加什么字段,文档和文档之间的字段不需要完全一致,比如A文档有是否拜师字段,B文档没有。

文档和文档之间的字段不需要完全一致
这样就完全不需要像 MySQL 那样提前定义表结构。
之前MySQL数据表里的一行数据,现在就成了一个文档。
既然MySQL的多行数据可以组合到一起,构成一张数据表,那多个文档也可以组合到一起,构成一个集合,又叫collection。
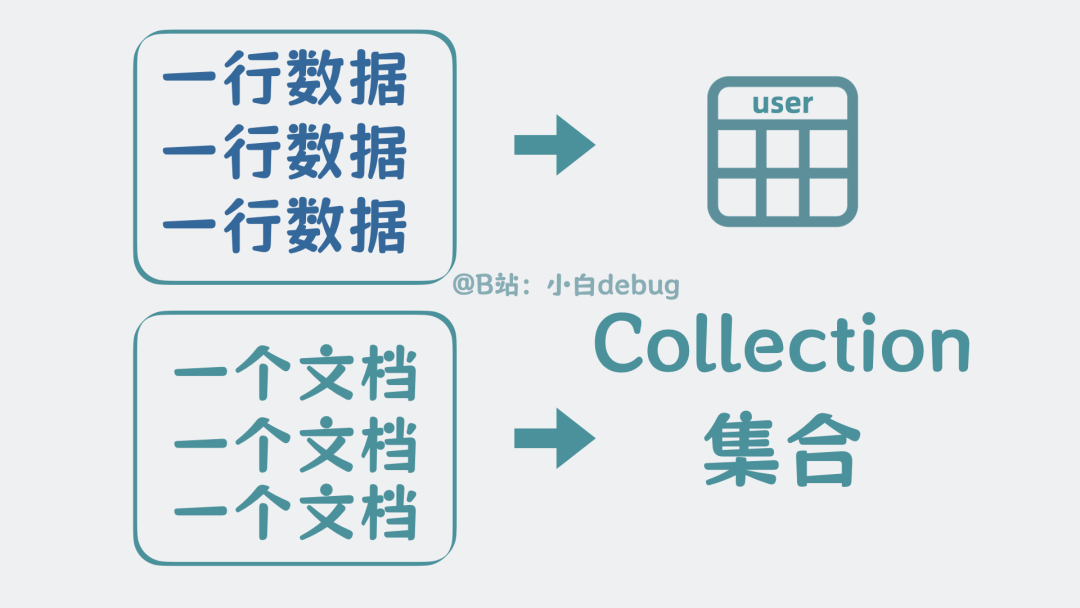
collection
文档和集合都是MongoDB里的核心概念。
如果说mysql是一个,用于读写数据表行列的服务进程,那MongoDB本质上就是个,用于读写集合文档的服务进程。
我们通常会使用SQL语句,读写MySQL的数据,MongoDB也有自己的查询语法,而且看起来跟SQL差异比较大,
比如MongoDB的find语句类似于mysql的select语句。updateOne就类似于mysql的update语句。
对应关系就像下面这样:

查询语句
接下来,我们假装不了解MongoDB,来看下它是怎么实现的。
看之前,你点赞了吗?关注了吗?谢谢!
BSON 编码
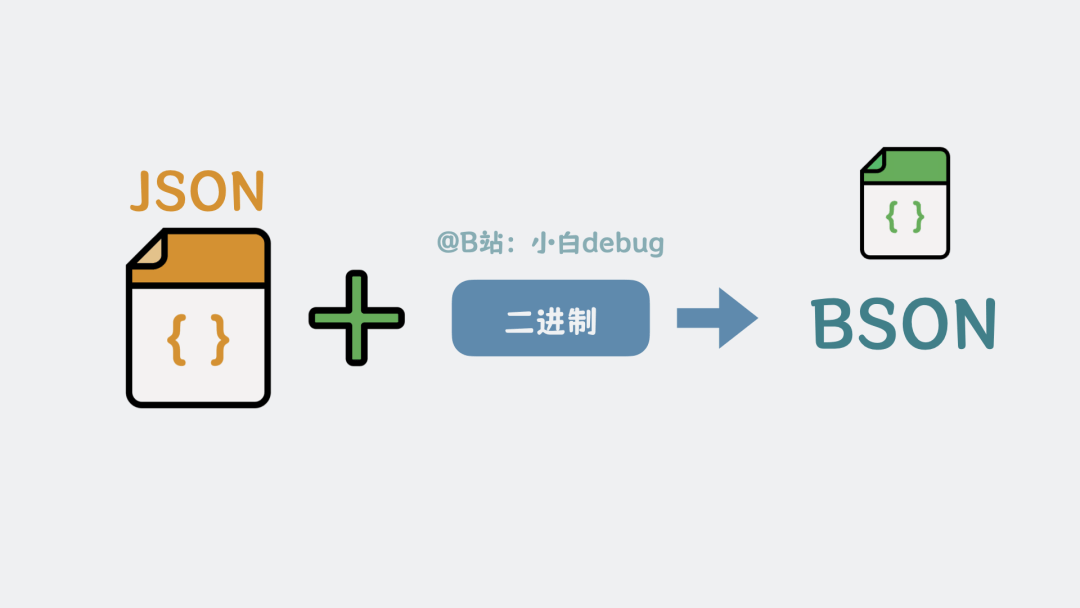
前面提到,文档长得像JSON,但JSON只支持数字,字符串这类基础类型,想要表达二进制这类常用存储类型,还要做一层Base64编码,不够高效,既然MongoDB的定位是存储,那当然要支持二进制的高效读写。所以,我们在JSON的基础上做下扩展,让它直接支持二进制等数据类型,也就成了二进制JSON,Binary JSON,简称BSON。
BSON数据页
有了BSON文档,下一步就是考虑将它们持久化到磁盘中。
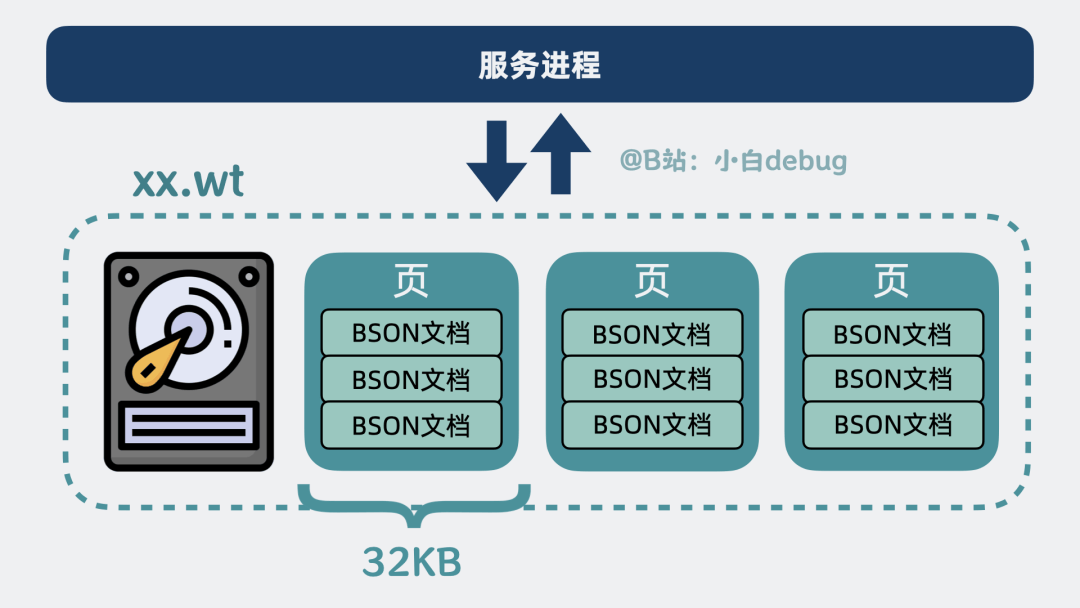
就像excel数据表在磁盘上是个.xls 文件,我们也可以将一个个BSON文档组成的集合,写到磁盘里.wt为后缀名的文件上。

wt后缀文件
集合越大,磁盘上的文件也就越大。
直接读写一个大文件里的全部数据会很慢,所以将数据拆成一个个数据页,每个页大小 32KB。
每个页大小 32KB
现在如果我们需要通过服务进程,读写某些个BSON文档数据,就只需要读写磁盘里的某几个数据页就好,不需要加载整个wt文件,大大减少了 IO 开销。
变种 B+ 树索引
集合里的多个文档,已经分散到多个32KB的数据页里,多个数据页又组成了.wt文件。
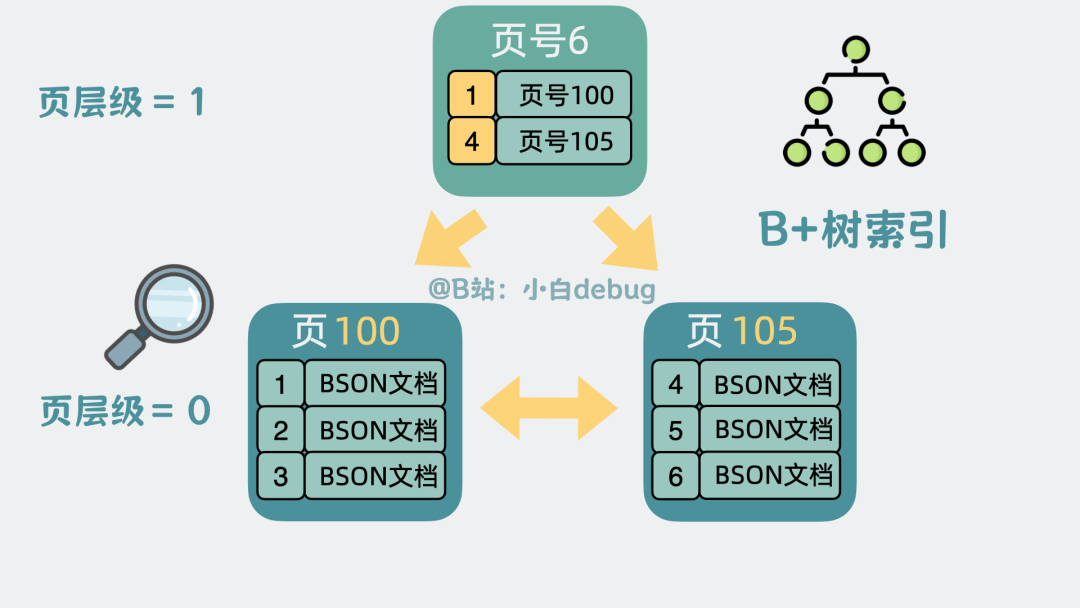
那问题就来了,如果我们已知某个文档主键_id,怎么快速找到包含这个文档的数据页呢?
好办,可以为每个数据页加入页号。
由于每个文档本身就自带一个_id主键,我们可以按主键大小排序,将每个数据页里最小的主键序号和所在页的页号提出来,放入到一个新生成的数据页中,并且给数据页加入层级的概念。
这样我们就可以通过上层的数据页快速缩小查找范围,最终定位到要查的数据页。通过这个方式,加速查找数据页的过程。
现在页跟页之间看起来就像是一棵倒过来的树,这棵可以加速查找数据页的树,就是我们常说的B+树索引。
B+树索引上面提到的是针对主键的索引,叫主键索引。

主键索引
按同样的思路,也可以为其他文档字段去建立索引,比如用户名字段,这样我们就能快速查找到名字为 xx 的用户有哪些,这就是所谓的辅助索引。
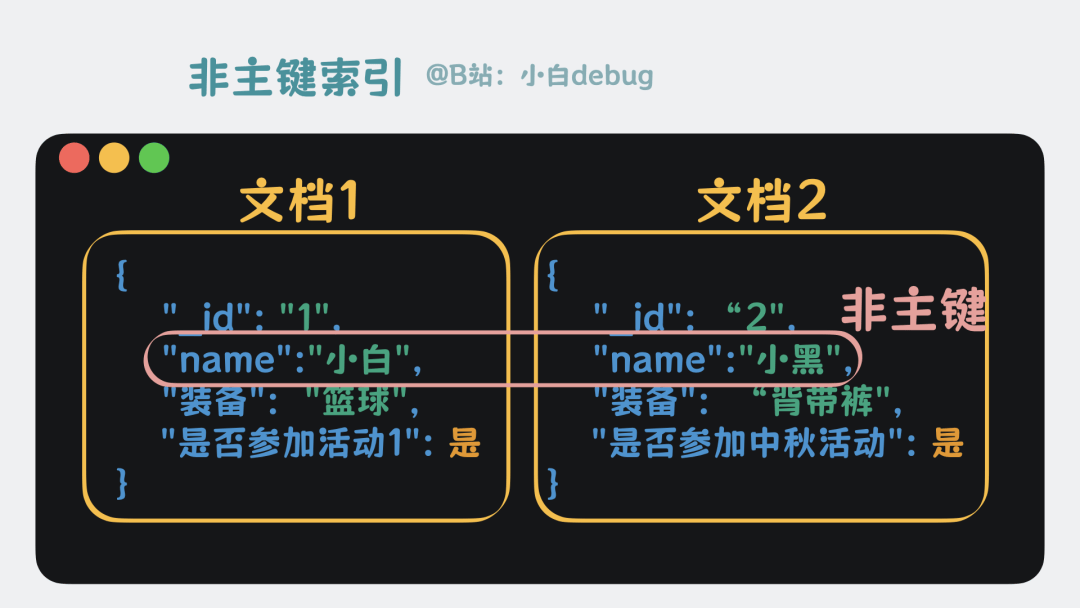
辅助索引
这一点跟mysql的B+树几乎一模一样,但不同的是,mysql更新B+树的数据页时,为了防止并发写冲突,从根到叶子节点的搜索中会加入短暂内存锁,并对目标叶的行记录加锁;而MongoDB写数据时,几乎不对数据页加锁,直接复制个新的数据页,出来写,也就是所谓的写时复制, Copy On Write,这样原来的数据页还能对外提供读操作,写操作则在新的数据页上进行,两者互不影响。
后面再找机会将复制出来的页合并到原有的B+树结构中,这样并发读写性能更好。
从效果上来看,就像是在原来的B+树基础上,挂了多个复制页,本质上是变种B+树。
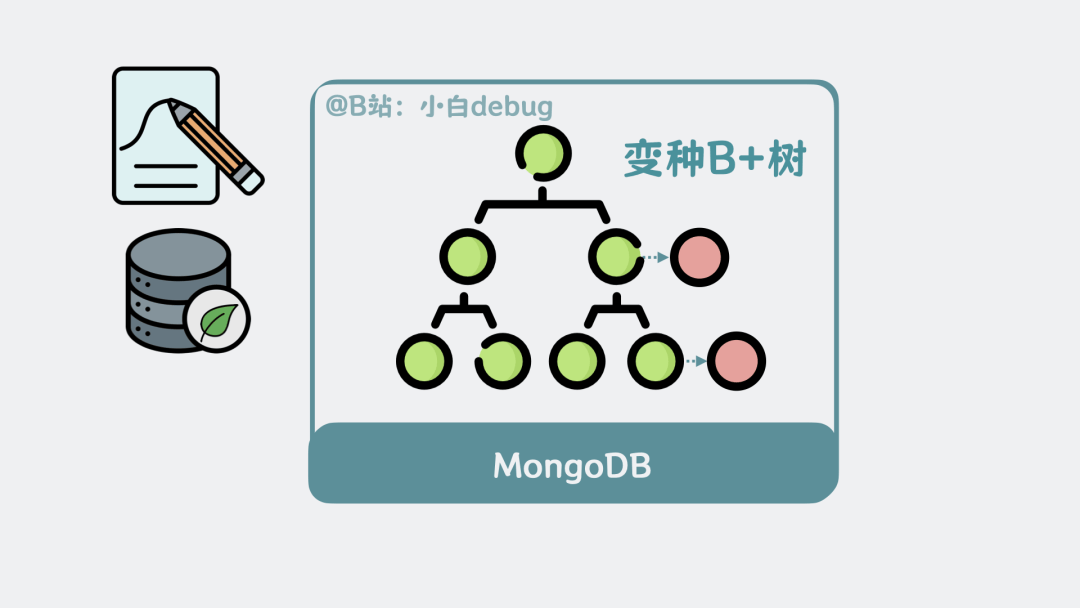
变种B+树
注意,网上有很多说mongodb底层用的是,非叶子节点包含完整文档数据的b树,别听他们的,以我为准。
加入缓存
有了索引,查询数据是变高效了,但数据本质上,还是在磁盘里,每次查询都要读磁盘,略慢了些。
怎么办呢?我们可以在服务进程里加个缓存,也叫Cache,把经常访问的磁盘热点数据页放到cache里,查询优先查cache,查不到再去查磁盘,这样磁盘IO变少,查询就快多了。
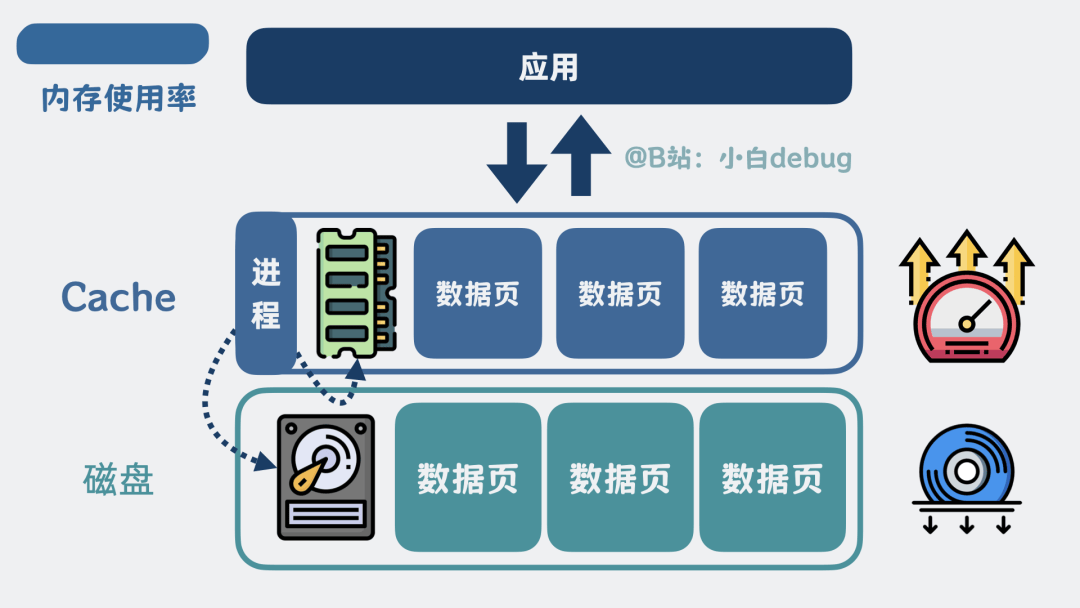
加个缓存
怕数据量太大内存扛不住,还可以根据一些策略删除掉一些内存。比如可以将最近最少使用的内存删掉,也就是, Least Recently Used, LRU,这样不仅解决了内存过大的问题,还让 缓存里的数据全是热点数据。真是一箭双雕。
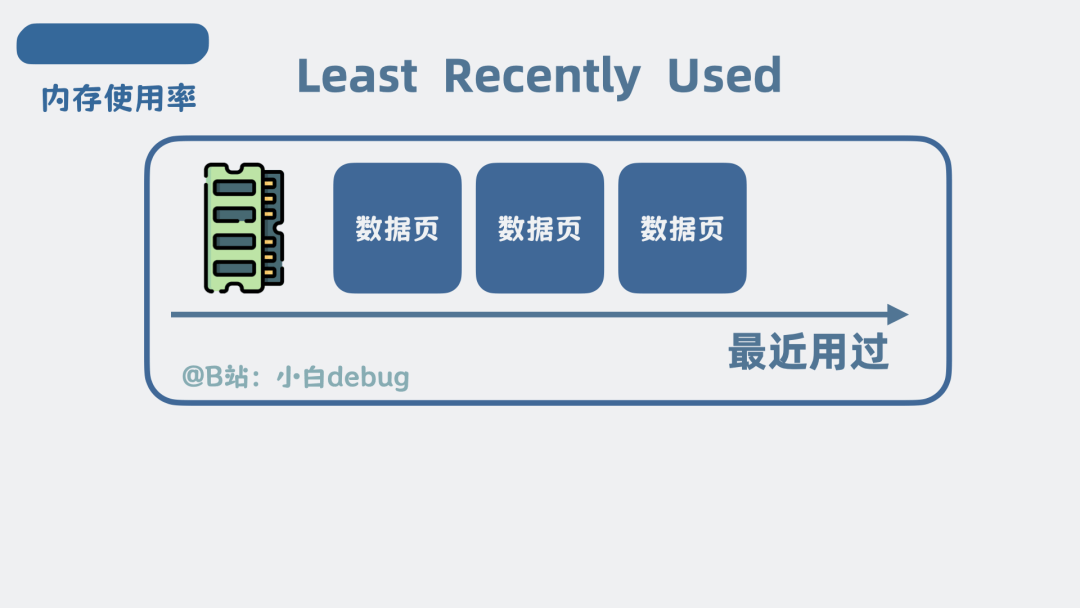
LRU写前日志 Journal
上面提到的Cache里的数据页,本质上都是内存。
如果服务崩了,内存里的数据页还没来得及写入磁盘,那数据不就丢了吗?有解法吗?
有!对所有写操作,都先将变更行为,记录到一个叫Journal Buffer的缓冲区里,然后再更新到数据页中,Journal Buffer的数据会定时刷到磁盘的Journal文件中。
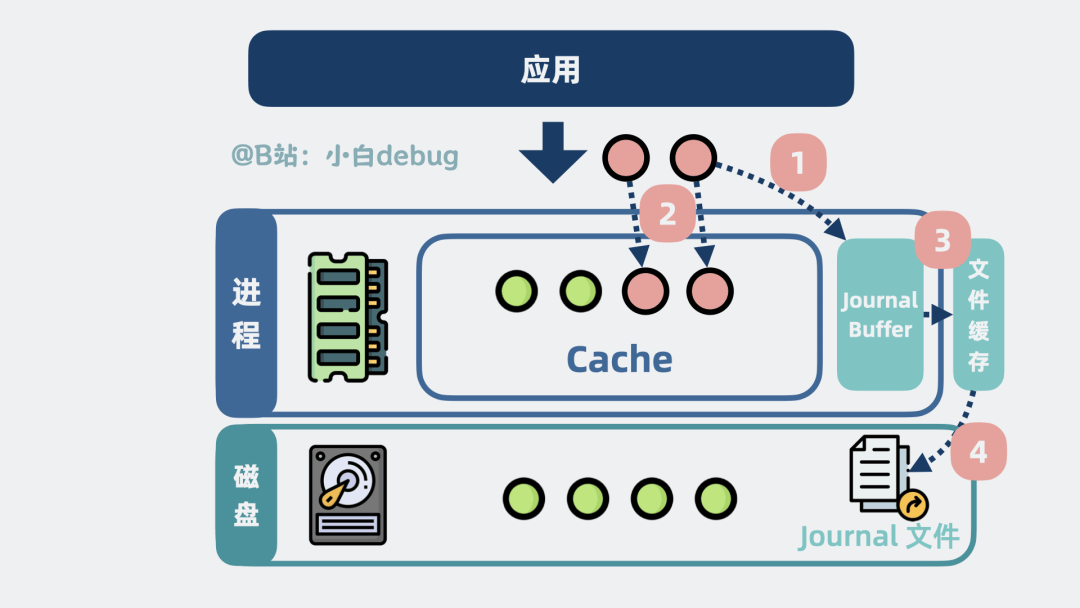
Journal是什么
如果服务进程崩溃了,那进程重启后,就能通过Journal文件找到历史操作记录,重做数据,尽可能保证数据不丢失。
这时候问题就来了,我有这功夫更新 Journal 文件,直接将 cache的数据写入到磁盘不香吗?
不太一样,Journal文件 是顺序写入的,cache 的内存数据是随机分散在磁盘各处的,顺序写磁盘性能是随机写的几十倍,所以很多存储系统在写数据时都会搞个日志来记录操作,方便服务重启后进行数据对账,确保数据的一致性和完整性,这类操作就是所谓的 Write-Ahead Logging (WAL) 。
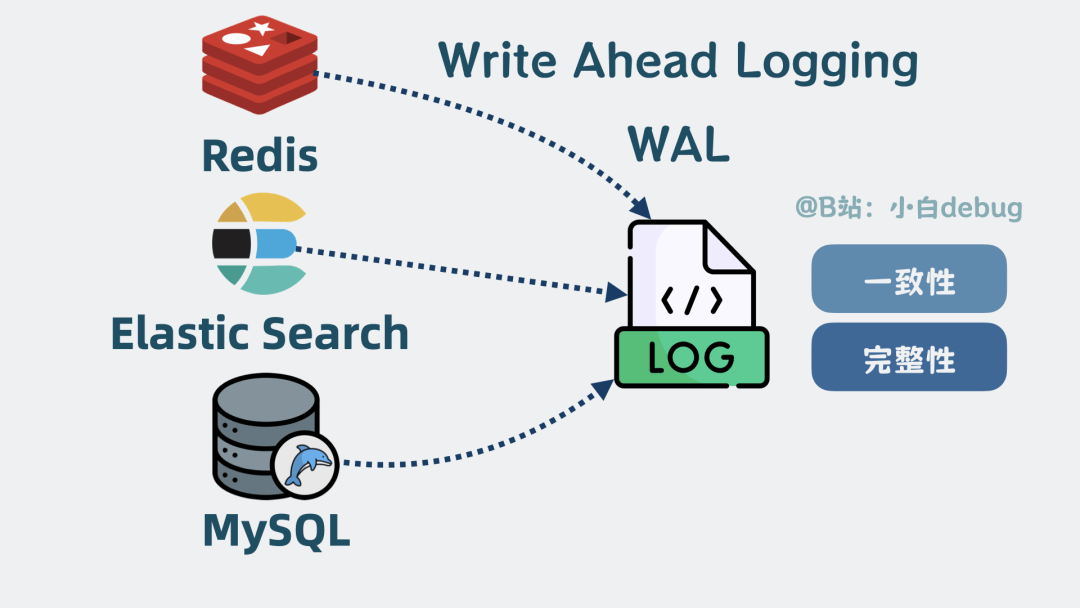
WAL是什么Checkpoint机制
注意,上面提到先记录Journal写操作,再更新数据页,此时数据依然在内存中,那内存中的数据什么时候写入磁盘呢?
如果等内存满了再写,一次写入量太大,性能会很差。如果写得太频繁,又会占用磁盘IO,影响读操作。
怎么办?
我们可以让系统,定期把内存中已修改但未写入磁盘的数据页,也就是脏页,一次性批量写入磁盘。这种定期批量写入的机制,这就是所谓的Checkpoint机制。
因为数据已经安全写入磁盘了,所以在这个时间点之前的Journal日志就可以删除了,不需要再保留这些历史操作记录。
WiredTiger是什么?
到这里,我们通过BSON文档,这种可以包含任意字段的数据结构,替代了mysql的行列的概念,让存储格式更加灵活。
将文档放入数据页和wt文件中,实现了高效的磁盘存储。
再通过变种B+树索引和写时复制机制,实现了快速数据查找和高并发写入。
为了进一步提升性能,引入了Cache,把热点数据放到内存中,大幅减少了磁盘IO。
用写前日志Journal和Checkpoint机制,保证了数据持久化。
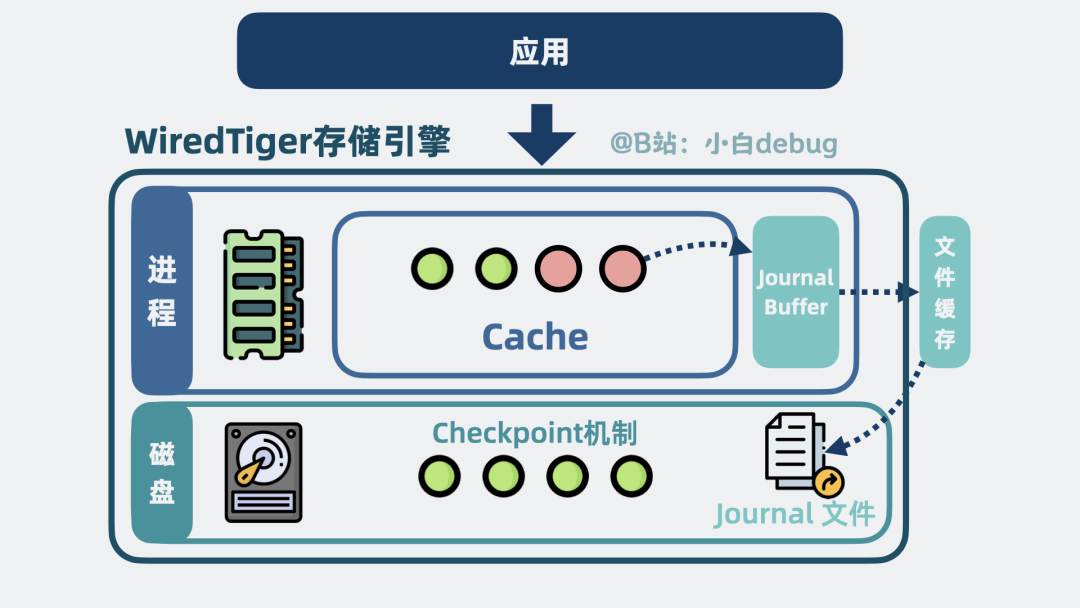
WiredTiger
它们共同构成了 WiredTiger存储引擎。并对外提供一系列函数接口。比如update用于更新数据,search用于查询数据。
我们平时写的mongodb查询语句,最终都会转换成 WiredTiger 提供的函数接口调用。
比如updateOne会转换为update方法。
find会转换为search方法。
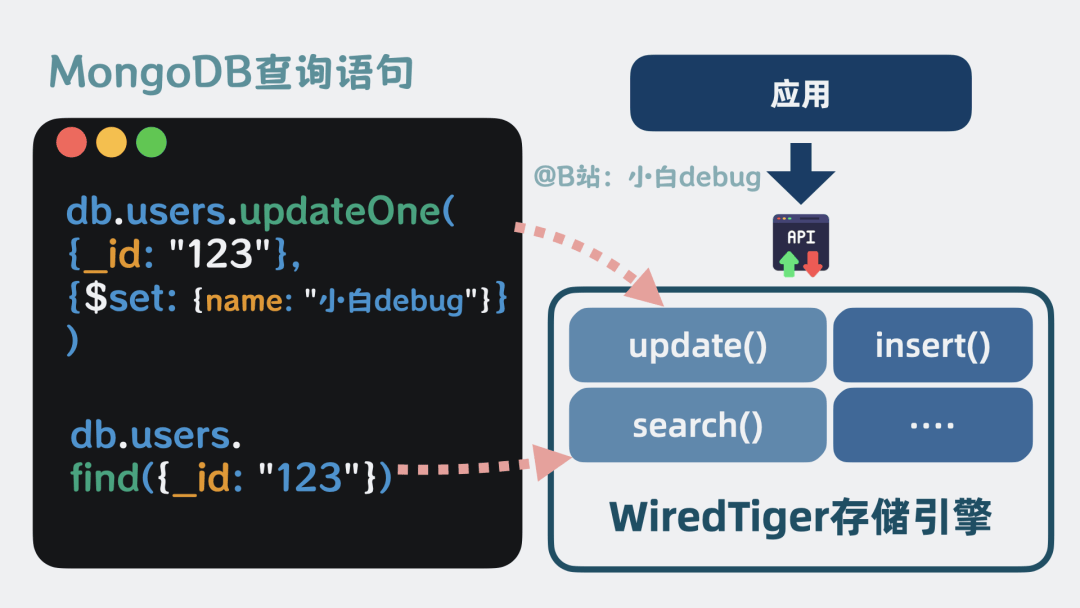
mongodb查询语句
但问题就来了,我们平时读写 mongodb 用的查询语句,是怎么转成存储引擎的函数接口的呢?
那就需要介绍 Server 层了。
Server 层架构
Server 层,本质上是mongodb查询语句 和 WiredTiger 存储引擎之间的中间层。
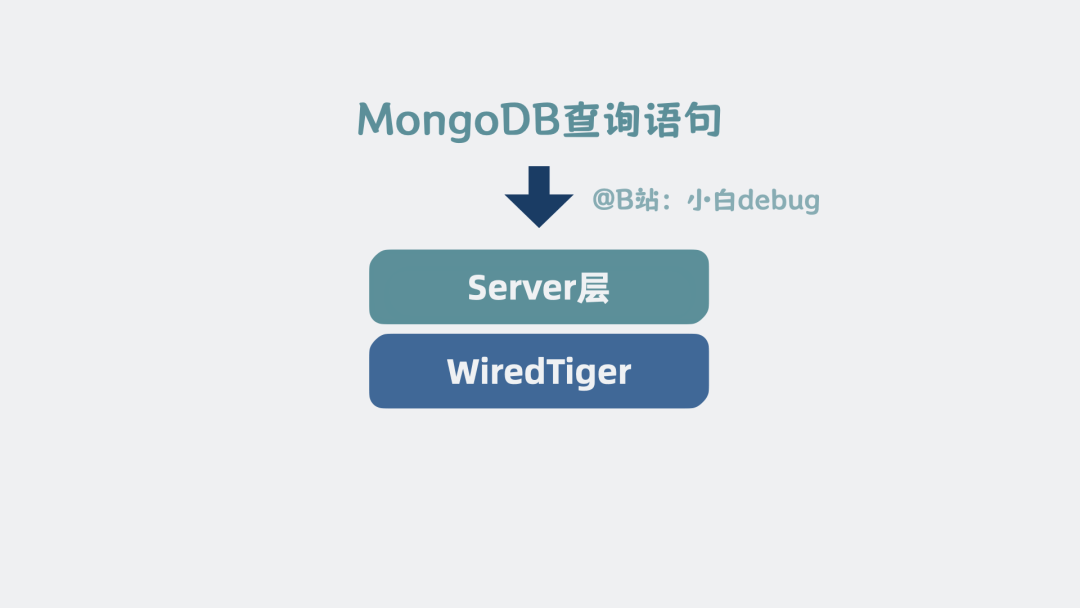
Server 层
它内部有一个连接管理模块,用于管理来自客户端应用的网络连接。
还有一个查询解析器,用于解析 MongoDB 的查询语句语法,判断查询语句有没有语法错误,比如字段名是否正确等。
再提供一个查询优化器,用于根据一定的规则选择该用什么索引,生成执行计划。
之后,提供一个执行器,根据执行计划去调用WiredTiger 存储引擎的接口函数。

server层内部
server 层和存储引擎层共同构成了一个完整的文档数据库,它就是我们常说的 MongoDB 数据库。

MongoDB 数据库
并且,查询引擎和存储引擎层是通过接口函数进行解耦的,换句话说就是,只要实现了上面这些接口函数,就能作为存储引擎与server层对接。
比如,MongoDB 早期用的是 MMAPv1 存储引擎,后来才支持的 WiredTiger。现在 WiredTiger 已经成为默认的存储引擎。
oplog 是什么
你听说过删库跑路吧,为了防止数据库表被删除带来的影响, server 层会将历史上所有变更操作记录到磁盘上的日志文件中,这个日志文件就是所谓的 oplog。一旦误删集合,就可以利用 oplog来恢复数据。
那么问题就来了,wiretiger 有一个 Journal日志 也做类似的事情,为什么还要多此一举?评论区告诉我答案。
单机MongoDB
如果你看过我之前做的「mysql」相关的视频,你会发现,mongodb和mysql的架构实现,惊人的相似。
我甚至演都不演了,很多素材都直接复用了。
如果说mysql本质上就是个通过b+树,读写数据页里行列数据的单机服务。那mongodb就是个通过变种b+树,读写数据页里集合数据的单机服务。
MongoDB在WiredTiger存储引擎的加持下,高性能是有了,但高可扩展和高可用是一点没看到。回到视频开头的问题,面对十亿级数据量时,单机CPU、内存、磁盘都会成为瓶颈。我们先看下怎么解决扩展性问题。
高扩展性
既然数据量太大,那我们就「切」。
将10亿条游戏用户数据,按主键ID范围切分,0到1kw放一个MongoDB里,1kw到2kw放另一个MongoDB里,每个MongoDB只处理1kw条数据。我们称每个MongoDB为一个分片。
再将多个MongoDB分片分散部署在多台机器上,每台机器就是一个Node。通过增加Node来缓解资源压力。
但这又引入了新问题,客户端应用怎么知道,某条数据存储在哪个分片上?
我们可以在客户端和分片之间,加一层路由服务,它可以根据查询条件,计算出数据在哪个分片,然后转发请求到分片中、收集分片的结果、合并排序后返回给客户端。这个路由服务,又叫mongos,当读写请求量变大时,mongos也可以扩展。
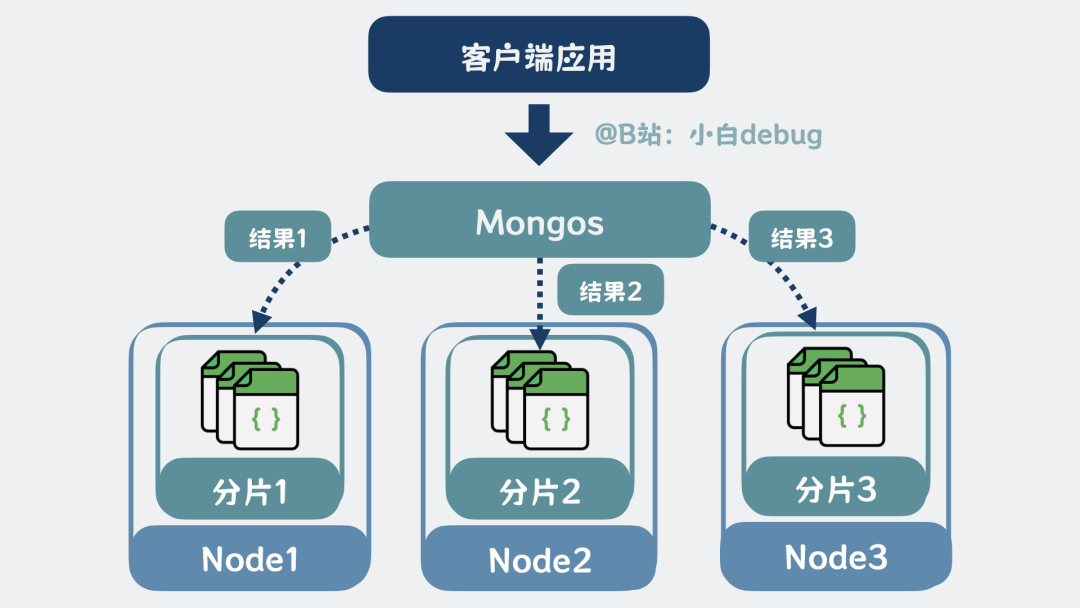
mongos是什么
mongos的配置信息,来自于配置服务器,Config Server,每个分片都连接config server,并主动上报自身信息,所以Config Server存储了有哪些分片,以及每个分片负责哪些数据范围等信息。
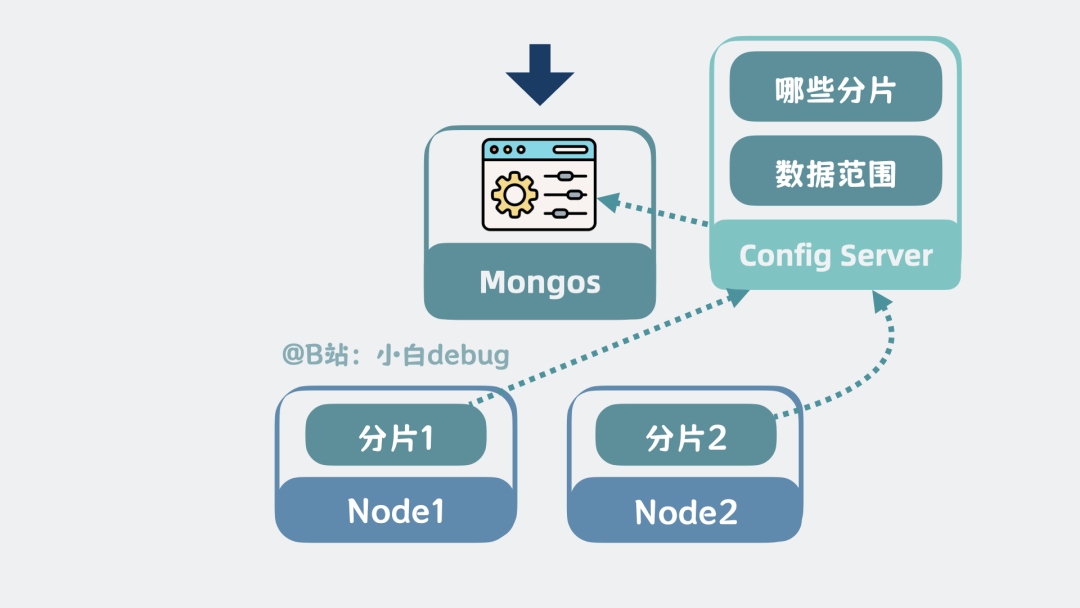
Config Server是什么高可用
到这里,问题又又来了,如果其中一个Node挂了,那Node里所有分片都无法对外提供服务了。怎么做到高可用?送分题了属于是,我们可以给每个分片都多加几个副本。
将分片分为主节点和副本节点。主节点将数据实时同步给副本节点,副本节点既可以对外提供读能力,还能在主节点挂了的时候,通过选举机制升级成新的主节点,保证系统高可用。
这种由一个主节点和多个副本节点组成的集群,就叫副本集,Replica Set,。有点类似于mysql的主从模式。

Replica Set分布式MongoDB集群
像这种通过多个MongoDB实例切分存储数据,实现扩展性,并通过mongos路由分发请求、聚合排序结果,通过Config Server管理配置信息,再给每个分片实例加入副本节点实现高可用的架构,就叫分布式MongoDB集群。
接下来我们用一个实际例子将上面提到的内容串起来,看看分布式MongoDB集群中的完整数据流程。
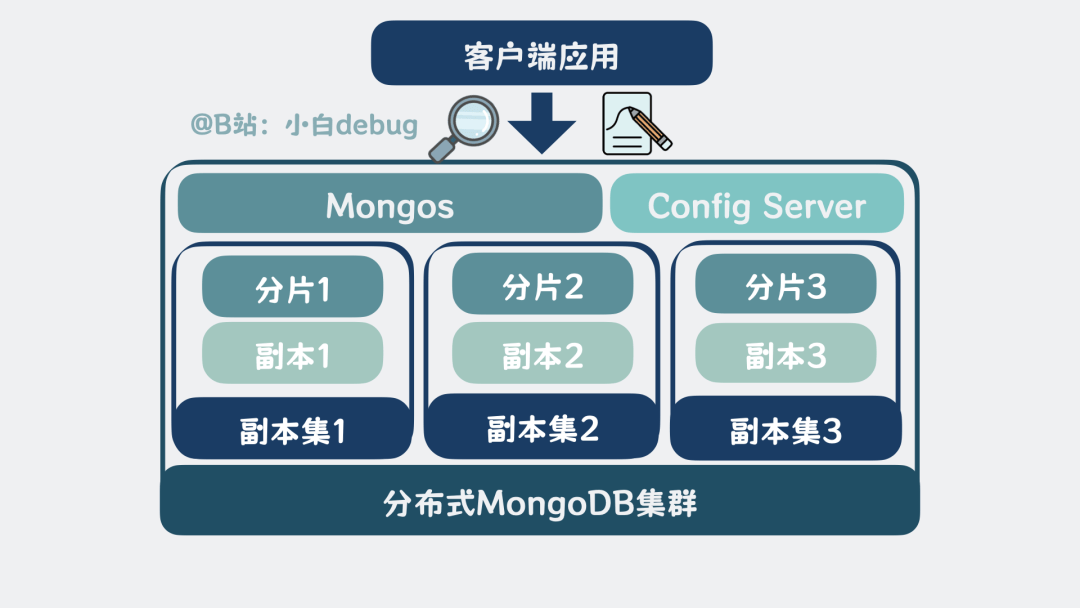
分布式MongoDB集群查询更新流程
不管是读还是写,客户端应用都会连接到mongos,发起请求。
mongos 根据请求,基于缓存的分片信息,确定数据在哪个分片上。必要时向 Config Server 刷新分片信息。
再将请求,转发到对应的分片副本集,注意这里可能涉及多个分片。
在每个MongoDB分片内部,客户端请求先到达分片的server层,经过查询解析器解析查询语法、查询优化器选择索引生成执行计划,再给到执行器调用WiredTiger的函数接口。
• 对于读操作,请求发送到WiredTiger存储引擎。WiredTiger先检查Cache中是否存在所需数据页,存在则直接返回。否则从磁盘读取数据页加载到cache中,再返回数据给mongos。mongos收集各分片的查询结果,进行合并、排序等处理,最终返回给客户端。
• 对于写操作,变更操作记录到Journal文件中,同时复制一份Cache的数据页,写入到复制页中。WiredTiger结合Checkpoint机制,将修改后的数据页写回磁盘。写操作完成后,分片主节点会将数据,实时同步给副本节点。当主节点和足够数量的副本节点都写入成功后,分片会返回写入确认给mongos。mongos收到所有相关分片的写入确认后,最终向客户端返回写操作成功的响应。
• 对于读操作,请求发送到WiredTiger存储引擎。WiredTiger先检查Cache中是否存在所需数据页,存在则直接返回。否则从磁盘读取数据页加载到cache中,再返回数据给mongos。mongos收集各分片的查询结果,进行合并、排序等处理,最终返回给客户端。
• 对于写操作,变更操作记录到Journal文件中,同时复制一份Cache的数据页,写入到复制页中。WiredTiger结合Checkpoint机制,将修改后的数据页写回磁盘。写操作完成后,分片主节点会将数据,实时同步给副本节点。当主节点和足够数量的副本节点都写入成功后,分片会返回写入确认给mongos。mongos收到所有相关分片的写入确认后,最终向客户端返回写操作成功的响应。
现在大家通了吗?
如果你觉得这个视频你有帮助,记得转发给你那不成器的兄弟。最后遗留一个问题, 你听说过养活国内大半自研数据库团队的PostgreSQL吗?你知道它的架构是怎么样的吗?返回搜狐,查看更多
评论 (0)