
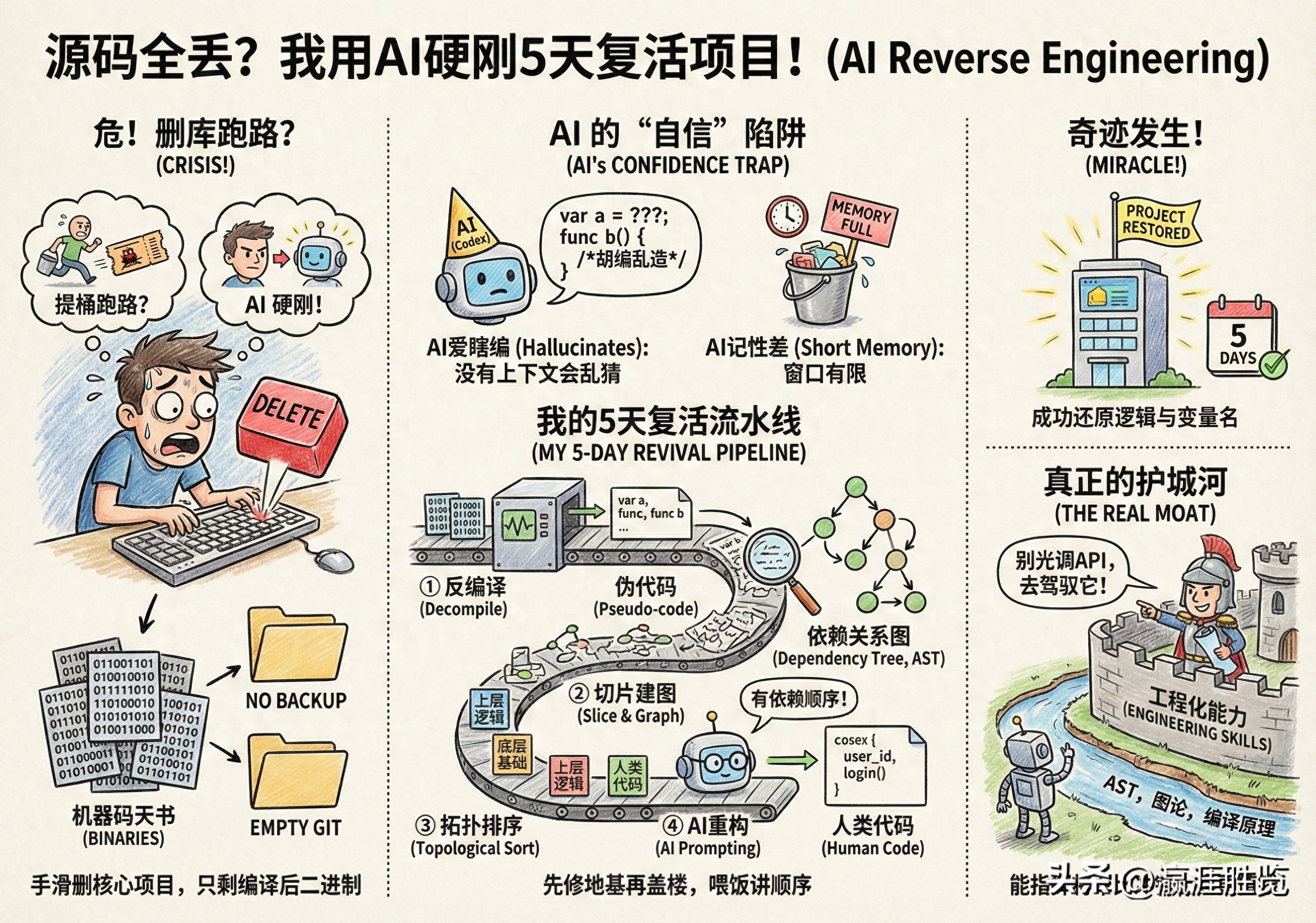
兄弟们,想象一个恐怖片级别的场景:
你手滑了,把公司核心项目的源码彻底删了。更绝望的是,本地没备份,Git 仓库也是空的,你手里只剩下一堆编译打包后、也就是那是给机器看、不是给人看的二进制“天书”。
这时候你是选择连夜买站票跑路,还是原地等死?
先别急着提桶。
这就是我最近经历的真实“鬼故事”。为了保住饭碗,我决定赌一把:用 AI(Codex)帮我把这些乱码“翻译”回源代码。
结果?我用了5天,真的把项目救回来了。
但过程绝不是你以为的“把代码扔给 AI,点击生成”那么简单。今天就把这套价值百万的“AI 逆向工程”复活术拆碎了讲给你听。
别被 AI 的“自信”骗了
很多人觉得现在的 AI 很强,扔进去一段混淆代码,它就能给你吐出完美源码。
大错特错。
如果你直接把一大坨代码扔给 Codex,它会表现得非常自信,给你生成一段看起来像模像样、但逻辑完全是胡编乱造的代码。
为什么?因为AI 是个“大话精”。
在没有足够上下文约束的情况下,它不仅会瞎猜变量名,还会凭空捏造函数逻辑。你敢用这种代码上线?那是嫌事故出的还不够大。
所以,核心难点只有两个:
AI 爱瞎编:怎么管住它的嘴,让它只基于逻辑还原?AI 记性差:上下文窗口有限,几万行代码不可能一次喂进去,怎么拆?破解“金鱼记忆”:喂饭也要讲究顺序
最棘手的问题是上下文长度(Context Window)。
一个复杂的项目,文件之间全是盘根错节的引用关系:A 文件调用 B,B 又依赖 C。
如果你只是把文件切成碎片随机喂给 AI,它根本不知道 utils.func() 到底是个啥,只能瞎猜。这就好比你让人读《红楼梦》,却是从第50回开始读,谁能看懂?
我的解决方案是:把代码变成“树”。
我搞了一套基于 AST(抽象语法树)的拓扑排序流水线。听着很吓人?其实逻辑很简单:
拆解:把大项目拆成一个个小的代码块(文件或函数)。找关系:分析谁调用了谁,画出一张“依赖关系图”。排队:利用拓扑排序,把最底层的、不依赖别人的代码(比如基础工具类)排在前面。投喂:先让 AI 还原基础代码,然后把这些“已知信息”作为上下文,去还原上一层代码。一句话总结:先修地基,再盖楼。 这样 AI 就能看着地基,推导出楼该怎么盖,而不是在空气里盖楼。
5天极限操作,我是怎么落地的?
为了不跑路,我搭建了一个自动化的“复活工厂”,流程如下:
第一步:反编译(Decompile)。先把那堆机器码通过工具转成人类勉强能看懂的“伪代码”。这时候的代码全是 var a, func b 这种鬼东西,完全没法维护。第二步:切片与建图(Slice & Graph)。用脚本扫描这些伪代码,提取引用关系,生成我上面说的“依赖关系图”。第三步:AI 逐个击破(Prompting)。这是最骚的一步。我写了一套 Prompt,告诉 Codex:“这是反编译的烂代码,这是它依赖的底层逻辑,请帮我重构回人类写的代码。”这时候,奇迹发生了。
因为有了正确的依赖顺序,AI 能够准确推断出 var a 其实是 user_id,func b 其实是 login()。它不仅还原了逻辑,甚至连变量名都起得八九不离十!
第四步:组装与测试。把 AI 生成的文件按目录结构重新拼好,跑通单元测试。真正的“护城河”在哪里?
看完这个过程,你是不是觉得:“嗨,这不就是调个 API 的事吗?”
千万别这么想。
这次经历让我明白,AI 时代的护城河,不是你会不会写 Prompt,而是你的工程化能力。
Codex 只是一个引擎(Engine)。能把这台引擎装进车里,让它跑起来的,是你对 AST(语法树)、图论(Graph Theory) 和 编译器原理 的理解。如果你不懂代码之间的依赖关系,不懂怎么把大问题拆解成小问题,给你再强的 AI,你也只能看着它一本正经地胡说八道。
这就是“高级工程师”和“API 调用侠”的区别。
别怕 AI,去驾驭它
这件事后,我没跑路,反而因为这套自动化工具在公司“封神”了。
不要把 AI 当成偷懒的工具,它是一个极度聪明但需要你引导的“超级实习生”。
你给它垃圾指令,它还你垃圾代码。你给它清晰的架构和逻辑,它能帮你创造奇迹。如果你也是开发者,别光顾着焦虑会不会被 AI 取代。去补补计算机基础,去学学怎么设计系统。
毕竟,能指挥千军万马的将军,永远比只会冲锋的士兵更值钱。
评论 (0)