搜索到
1021
篇与
的结果
-
 MySQL8.0.45安装教程 Mysql官方地址https://www.mysql.com/cn/downloads/进来之后点击下载滑倒最下面点击箭头指向的链接进来之后点击进来之后选择需要下载的安装包版本、环境以及在线/离线,这里我们选择离线版本。点击直接下载下载好之后,打开安装包,选择最后一个Custom(自定义安装),点击next左侧层级点最后的Mysql server 版本号 点第一个绿色箭头加入到右侧中,再点击next如果想自定义安装mysql目录的话可以图示先点击右侧然后点击下面选择安装目录和数据目录点击excute执行100%后点击nextnextmysql的默认端口3306不做修改点击next授权方式我们选择第二个传统授权输入你的root密码, next(记住是常用的别忘记了 最好记事本记录下来)nextnextexcute执行点击finshnextfinsh配置环境变量如果是默认安装路径就是下面的路径如果修改了安装路径则找到安装目录bin下并复制路径C:\Program Files\MySQL\MySQL Server 8.0\bin右键我的电脑->属性->高级系统设置->系统环境变量->path添加保存即可。验证安装WIN+R cmd打开命令窗口输入mysql -h localhost -u root -p再输入数据库密码登录成功navicat链接输入主机地址、端口号、账号、密码点击测试连接。如果是已安装mysql的用户想重新安装mysql记得卸载掉mysql后记得检查注册表我用的是geek卸载可以直接删掉注册表注册表地址计算机\HKEY_LOCAL_MACHINE\SYSTEM\ControlSet001\Services\EventLog\Application\MySQL删掉注册表之后以管理员身份打开cmd窗口输入sc delete MySQL80 删掉之前安装mysql用到的名字sc delete MySQL80最好是重启一下或者检查本地服务有没有占用3306端口。
MySQL8.0.45安装教程 Mysql官方地址https://www.mysql.com/cn/downloads/进来之后点击下载滑倒最下面点击箭头指向的链接进来之后点击进来之后选择需要下载的安装包版本、环境以及在线/离线,这里我们选择离线版本。点击直接下载下载好之后,打开安装包,选择最后一个Custom(自定义安装),点击next左侧层级点最后的Mysql server 版本号 点第一个绿色箭头加入到右侧中,再点击next如果想自定义安装mysql目录的话可以图示先点击右侧然后点击下面选择安装目录和数据目录点击excute执行100%后点击nextnextmysql的默认端口3306不做修改点击next授权方式我们选择第二个传统授权输入你的root密码, next(记住是常用的别忘记了 最好记事本记录下来)nextnextexcute执行点击finshnextfinsh配置环境变量如果是默认安装路径就是下面的路径如果修改了安装路径则找到安装目录bin下并复制路径C:\Program Files\MySQL\MySQL Server 8.0\bin右键我的电脑->属性->高级系统设置->系统环境变量->path添加保存即可。验证安装WIN+R cmd打开命令窗口输入mysql -h localhost -u root -p再输入数据库密码登录成功navicat链接输入主机地址、端口号、账号、密码点击测试连接。如果是已安装mysql的用户想重新安装mysql记得卸载掉mysql后记得检查注册表我用的是geek卸载可以直接删掉注册表注册表地址计算机\HKEY_LOCAL_MACHINE\SYSTEM\ControlSet001\Services\EventLog\Application\MySQL删掉注册表之后以管理员身份打开cmd窗口输入sc delete MySQL80 删掉之前安装mysql用到的名字sc delete MySQL80最好是重启一下或者检查本地服务有没有占用3306端口。 -
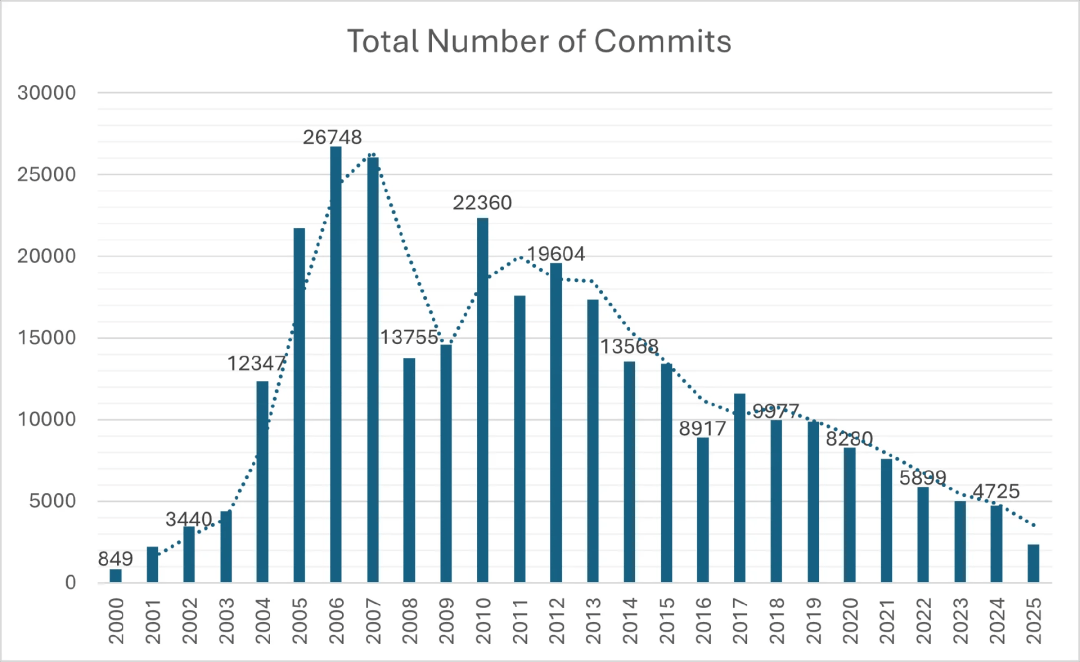
MySQL 代码库分析报告显示,开发活动衰退且贡献者数量减少 作者 | Renato Losio译者 | 平川 最近,一份报告 分析 了 MySQL 服务器代码库的统计数据,为的是评估项目的状态、甲骨文对 MySQL 的投入以及社区版的未来。Percona 软件工程师经理 Julia Vural 写道:MySQL 数据库服务器是开源世界的基石。尽管其影响力不容置疑,但在查看其核心源代码库的原始统计数据时,我们发现了其不断发展变化而且有时令人惊讶的开发历史……年度提交视图存在明显的波动,也清楚地证实了其中存在的长期下降趋势。……仅根据历史提交量来看,该项目的活跃度预计将继续下降。根据分析,积极参与 MySQL 开发的开发人员人数量已从 2006 年的峰值 198 人降至 2025 年的约 75 人。与此同时,在过去 14 年间,代码更新量年均减少约四分之三,表明该项目的整体投入正在减少。图片来源:Percona 博客Vural 总结道:从 2011 年以来的总体趋势来看,提交数量持续下降,独特贡献者数量减少。该趋势线发出了一个明确的警告:如果不进行干预,预计总体开发速度将会进一步放缓。然而,针对 Heatwave 项目日益集中的投入表明,开发资源正被战略性地分配至更广泛的 MySQL 生态系统中那些高优先级的商业化计划。报告表明,每年新增的核心编程代码量一直在下降,这可能是因为软件已经成熟,也可能是因为开发工作已经转移到专有版本。一些开发人员 要求 对 PostgreSQL 代码库进行类似的分析,以便可以更好地比较这两种趋势。今年早些时候,甲骨文 解雇了大量从事 MySQL 社区版开发的开发人员,部分最新的主要功能仅在 MySQL Heatwave(OCI 上的托管服务)和 MySQL 企业版中提供,这引发了社区的进一步担忧。MariaDB 联合创始人 Patrik Backman 写道:甲骨文能在多大程度上削减 MySQL 的工程投入,而又不会导致开发人员关注度开始流失?大型企业会在多长时间内接受功能锁定成为业务连续性的代价?正如 InfoQ 之前的报道,MySQL AI 仅针对企业版推出,为添加向量支持,PlanetScale 创建了社区版的一个分叉。Meta 也创建了 MySQL 的一个分叉,为的是添加诸如 Raft 共识引擎、RocksDB 和 向量存储 等功能。同样,社区版目前尚未提供 Java 函数和过程 支持。分析使用的数据是从官方 MySQL 服务器的本地克隆中提取的,分析过程使用自定义的 Python 脚本,利用格式化的 Git 日志命令提取每个提交的关键指标。返回搜狐,查看更多
-
面试官:已经有锁了,Mysql为什么还要引入MVCC? 面试刷题网站:今天我们来聊一个MySQL面试中的高频考点,也是每一位后端开发者都应该深度掌握的核心知识——MVCC协议。MVCC,全称是多版本并发控制(Multi-Version Concurrency Control),它是MySQL InnoDB存储引擎用以实现高效并发访问的基石。在面试中,这几乎是一个无法绕开的话题,透过它,就能通向对事务、隔离级别、锁机制等一系列更深层次知识的探讨。因此,彻底搞懂MVCC,能让你在面试中游刃有余,从容地展现自己的技术深度。在接下来的内容里,我将带你从MVCC的底层原理出发,不仅让你理解它“是什么”,更让你明白它“为什么”如此设计,以及如何在面试中将这些知识转化为你的优势。在正式开始之前,我们先来思考一个最根本的问题:在已经有锁机制的情况下,InnoDB为什么还需要费尽心机地引入MVCC呢?1. MVCC有什么用你可能已经对数据库的锁机制有所了解,知道它是保障数据一致性、进行并发控制的基础工具。那么,既然已经有了锁,为什么InnoDB还要多此一举引入MVCC呢?直接用读写锁把所有并发访问都管起来,不是更简单直接吗?答案是:单纯依赖锁,性能实在太差了。在一个纯粹的锁模型中,为了保证绝对的数据一致性,操作之间的互斥是不可避免的。写操作会阻塞其他写操作,这理所当然。但更致命的是,写操作同样会阻塞读操作。即使用了所谓的“读写锁”(允许多个读操作并发,但读写、写写互斥),读与写之间的冲突依然存在。数据库系统与常规的应用程序有一个显著的区别:它承载着高频的读写请求,尤其是读取操作,其性能表现至关重要。想象一下这个业务场景:一个核心业务线程正在执行UPDATE操作修改某一行关键数据,哪怕这个操作只需要几十毫秒,但在这期间,所有希望读取这行数据的SELECT请求都被迫挂起等待。在高并发系统中,这种阻塞会迅速累积,导致系统吞吐量急剧下降,用户响应时间大幅延长。这样的性能表现,在真实的线上环境中是绝对无法接受的。展开全文显然,为了挣脱这种性能枷锁,数据库必须寻求一种更优的解决方案,实现一种“读写并发”的理想状态:当我在修改数据时,你依然可以无阻塞地读取数据。这就是MVCC诞生的核心驱动力。它通过一种巧妙的方式,让读和写在大多数时候可以各行其道,互不干扰。理解了MVCC存在的价值后,我们才能更好地去探究它的实现细节。而要理解MVCC,就必须先掌握一个与之紧密相连的前置概念——事务的隔离级别。2. 事务的隔离级别数据库的隔离级别,本质上是定义的一套“游戏规则”,它用于规范在并发环境下,一个事务的修改对其他事务的可见性程度。换句话说,它界定了事务之间“互相了解”的边界。ANSI/ISO SQL标准定义了四种隔离级别:读未提交(Read Uncommitted)读未提交(Read Uncommitted)这是最低的隔离级别。在此级别下,一个事务可以看到另一个事务尚未提交的修改,因此风险极高,可能会导致“脏读”。读已提交(Read Committed, RC)读已提交(Read Committed, RC)这是大多数主流数据库(如Oracle、PostgreSQL)默认的隔离级别。一个事务只能看到其他事务已经提交的修改。这确保了你读到的数据至少是“真实存在”过的。但问题在于,在一个事务的执行过程中,如果其他事务提交了新的修改,本事务后续的查询是能够看到这些新变更的,从而导致“不可重复读”。可重复读(Repeatable Read, RR)可重复读(Repeatable Read, RR)这是MySQL InnoDB存储引擎的默认隔离级别。它保证了在一个事务内部,无论你对同一份数据读取多少次,得到的结果始终是一致的。这意味着,一旦事务开始,它就仿佛进入了一个“时间凝固”的快照中,即使在此期间有其他事务提交了修改,当前事务也“视而不见”。串行化(Serializable)串行化(Serializable)这是最高的隔离级别。它通过对所有读写操作都加锁的方式,强制所有事务串行执行,一个接一个地排队处理。这能够完全避免所有的并发问题,但代价是并发性能急剧下降,几乎回到了单线程时代。从上到下,隔离性越来越强,数据一致性保障越好,但并发性能也随之下降。因此,选择合适的隔离级别,是在业务需求和系统性能之间进行权衡的艺术。与隔离级别相伴而生的,是三个经典的并发读问题:脏读(Dirty Read):指读到了其他事务还未提交的数据。这些数据因为随时可能被回滚而消失,所以被称为“脏”数据,是极不稳定的。不可重复读(Non-Repeatable Read):指在同一个事务中,对同一行数据前后两次读取,得到的结果不一致。其关注点在于数据内容的变更。幻读(Phantom Read):指在一个事务的执行过程中,另一个事务插入了新的数据行并提交,导致第一个事务在后续的查询中,读到了之前不存在的“幻影”行。其关注点在于数据行数的增减。脏读(Dirty Read):指读到了其他事务还未提交的数据。这些数据因为随时可能被回滚而消失,所以被称为“脏”数据,是极不稳定的。不可重复读(Non-Repeatable Read):指在同一个事务中,对同一行数据前后两次读取,得到的结果不一致。其关注点在于数据内容的变更。幻读(Phantom Read):指在一个事务的执行过程中,另一个事务插入了新的数据行并提交,导致第一个事务在后续的查询中,读到了之前不存在的“幻影”行。其关注点在于数据行数的增减。我们可以用一个表格来清晰地展示隔离级别与这三种读问题的关系:隔离级别脏读不可重复读幻读读未提交可能可能可能读已提交不可能可能可能可重复读不可能不可能可能串行化不可能不可能不可能这里需要特别强调一点:根据SQL标准,可重复读隔离级别是无法完全避免幻读的。但是,MySQL的InnoDB引擎通过引入**临键锁(Next-Key Lock)**这一强大的锁定机制,在RR级别下巧妙地解决了幻读问题。在面试中提及这一点,并能解释其原理,无疑会是一个重要的加分项。此外,还有两个概念需要精确区分:快照读(Snapshot Read)和当前读(Current Read)。简单理解,快照读(如普通的SELECT)读取的是MVCC机制提供的历史版本数据,它无须加锁,速度很快。而当前读(如SELECT ... FOR UPDATE、UPDATE、DELETE)读取的是数据库中最新的、已提交的版本,并且会对读取的记录加锁,以保证数据的一致性。在MySQL的可重复读隔离级别下,普通的SELECT语句执行的就是快照读。3. 版本链为了实现MVCC,InnoDB为表中的每一行数据都额外增加了两个隐藏的系统字段:trx_id和roll_ptr。trx_id(Transaction ID):事务ID。MVCC中的“V”(Version)指的就是由不同事务ID创造的数据版本。每当一个事务开始时,它会获得一个唯一的、单调递增的事务ID。当这个事务修改某行数据时,该行的trx_id就会被更新为当前事务的ID。roll_ptr(Rollback Pointer):回滚指针。它是一个指向undo log中上一版本记录的指针。InnoDB正是通过这个指针,将一行数据的多个历史版本像链表一样串联起来,形成一个“版本链”。trx_id(Transaction ID):事务ID。MVCC中的“V”(Version)指的就是由不同事务ID创造的数据版本。每当一个事务开始时,它会获得一个唯一的、单调递增的事务ID。当这个事务修改某行数据时,该行的trx_id就会被更新为当前事务的ID。roll_ptr(Rollback Pointer):回滚指针。它是一个指向undo log中上一版本记录的指针。InnoDB正是通过这个指针,将一行数据的多个历史版本像链表一样串联起来,形成一个“版本链”。实际上,InnoDB还有一个隐藏的row_id列,在没有显式定义主键时,它会作为内部主键。但它与MVCC的并发控制逻辑关系不大,我们在此不做过多关注。下面,我们通过一个具体的例子来直观地理解版本链是如何构建的。假设我们向表中插入一条新数据{id: 1, x: 130},执行该操作的事务ID为100。此时,这行数据的最新版本状态如下:现在,一个新的事务A(ID为101)启动,并将x的值修改为150。这时,数据库并不会直接覆盖原始数据,而是会执行以下操作:将原始行数据{id: 1, x: 130, trx_id: 100}完整地拷贝到undo log中。在原始数据行上进行修改,将x更新为150,并将trx_id更新为当前事务的ID,即101。将这行新数据的roll_ptr指向刚刚在undo log中创建的旧版本记录。将原始行数据{id: 1, x: 130, trx_id: 100}完整地拷贝到undo log中。在原始数据行上进行修改,将x更新为150,并将trx_id更新为当前事务的ID,即101。将这行新数据的roll_ptr指向刚刚在undo log中创建的旧版本记录。修改后,数据行的最新状态变为:接着,又来了一个事务B(ID为102),它将x的值从150修改为200。同样地,数据库会重复上述过程,将trx_id为101的版本拷贝到undo log,然后更新数据行的最新版本,并将roll_ptr指向trx_id为101的版本。这样一来,通过roll_ptr,一行数据的多个历史版本就被从新到旧地串联成了一条链表。这条链就是大名鼎鼎的版本链。现在问题来了:如果一个新的事务C想要读取x的值,它面对的是一条长长的版本链,它应该读取哪个版本的数据呢?这就引出了MVCC的另一个核心裁决机制:Read View。3.1 Read View(读视图)你可以将Read View(读视图)理解为一套在特定时刻生成的“可见性规则快照”。当一个事务需要进行快照读时,数据库会依据这个Read View来扫描版本链,判断哪个版本是对当前事务可见的。Read View主要在“读已提交(RC)”和“可重复读(RR)”这两个隔离级别下工作。它们的核心区别,就在于生成Read View的时机。读已提交(RC):事务中每一次SELECT查询开始时,都会重新生成一个新的Read View。可重复读(RR):仅在事务第一次SELECT查询时,生成一个Read View,并在此后的整个事务期间都复用这个Read View。读已提交(RC):事务中每一次SELECT查询开始时,都会重新生成一个新的Read View。可重复读(RR):仅在事务第一次SELECT查询时,生成一个Read View,并在此后的整个事务期间都复用这个Read View。这个区别可以用一个形象的比喻来描述:RC隔离级别像一个每次约会都换新对象的“花心大少”,他眼中的世界总是在变化;而RR隔离级别则像一个从始至终只认初恋的“痴情种子”,无论外界如何变迁,他眼中的恋人永远是最初的模样。3.2 Read View与读已提交(RC)在RC隔离级别下,每次查询都会生成新的Read View,这意味着在事务执行过程中,可见性判断的基准是动态变化的。我们来看一个例子。假设当前数据库中有三个事务修改过的历史版本,状态如下:现在,一个新的事务A(trx_id为4)启动了。当它第一次查询x的值时,MySQL会创建一个Read View。此时,活跃(未提交)的事务ID集合是m_ids = {2, 3}。事务A会沿着版本链从最新版本开始查找,它会跳过trx_id为3和2的版本(因为它们的事务ID在活跃事务列表m_ids中,意味着它们是“未提交”或“并发”的事务),最终找到trx_id为1的版本。这个版本已经提交,所以事务A读到的x的值是10。紧接着,事务2提交了。然后事务A在同一个事务内再次查询x。由于是RC隔离级别,MySQL会重新生成一个Read View。此时,活跃事务列表变成了m_ids = {3}。事务A再次沿着版本链查找,它会跳过trx_id为3的版本,但当它检查到trx_id为2的版本时,发现2已经不在新的活跃列表m_ids中了(意味着事务2已提交),于是它读取了这个版本的数据。因此,事务A这次读到的x的值是40。这就是“不可重复读”的由来。3.3 Read View与可重复读(RR)在RR隔离级别下,Read View在事务第一次查询时创建,并在整个事务期间保持不变。我们用同样的例子来说明。当事务A(ID为4)第一次查询时,创建了一个Read View,其活跃事务列表为m_ids = {2, 3}。此时,事务A查询x的值,与RC级别下的第一次查询一样,它会忽略trx_id为2和3的未提交版本,最终读到trx_id为1的版本,结果为x=10。接下来,即使事务2提交了,当事务A再次查询x的值时,它使用的仍然是事务开始时创建的那个旧的Read View。在这个旧的Read View中,m_ids依然是{2, 3}。所以,对于事务A来说,事务2看起来仍然是“未提交”的(因为事务2的ID存在于它持有的那个旧的Read View的m_ids列表中)。因此,它会再次忽略trx_id为2的版本,最终读到的结果仍然是x=10。这就是“可重复读”的实现原理。无论其他事务如何提交,当前事务的“视界”在事务开始的那一刻就已经被固定下来了。3.4 Read View小结为了让你更清晰地理解,我将上述过程总结为两张图。读已提交(RC)下的Read View变化:可重复读(RR)下的Read View固定:实际上,一个完整的Read View除了m_ids(活跃事务ID列表)外,还包含其他几个关键字段,共同构成了可见性判断的完整逻辑:m_up_limit_id:m_ids列表中的最小事务ID。任何trx_id小于此值的版本,都表示是“已提交”的,因此可见。m_low_limit_id:当前系统中下一个将被分配的事务ID。任何trx_id大于等于此值的版本,都表示是“未来”的事务,因此不可见。m_creator_trx_id:创建该Read View的事务自身的ID。自身的修改总是可见的。m_up_limit_id:m_ids列表中的最小事务ID。任何trx_id小于此值的版本,都表示是“已提交”的,因此可见。m_low_limit_id:当前系统中下一个将被分配的事务ID。任何trx_id大于等于此值的版本,都表示是“未来”的事务,因此不可见。m_creator_trx_id:创建该Read View的事务自身的ID。自身的修改总是可见的。可见性判断的完整规则可以概括为:对于一个版本链上的数据行,其trx_id会与Read View的这几个字段进行比较,以确定其是否可见。不过,在面试中,你只需要记住核心逻辑——m_ids和Read View的创建时机——就足以理解MVCC的精髓了。4. 面试实战指南掌握了前面的基础知识,我们来看看在面试中如何将这些知识转化为你的优势。首先,你必须清楚自己公司生产环境数据库的隔离级别。如果不是默认的RR,那你一定要搞清楚为什么要做这样的调整,这本身就是一个很好的实践案例。面试官可能会现场构造一个并发场景来考察你。我的建议是,对这类问题提前做好心理准备。如果一时反应不过来,不要慌张,可以礼貌地请面试官慢速复述一遍问题,甚至可以主动请求使用纸笔,将版本链和Read View的演变过程画出来再分析,这不仅能帮助你理清思路,还能向面试官展示你扎实、严谨的分析能力。4.1 基本思路当面试官从锁的问题过渡到MVCC,问“为什么有了锁还需要MVCC”时,你的回答要突出关键词:避免读写阻塞,实现读写并发。“单纯使用锁机制,并发性能会很差。即使是读写锁,读和写操作之间仍然是互斥的。数据库作为高性能中间件,如果一个写操作就导致所有读操作被阻塞,这种性能损失是无法接受的。因此,InnoDB引擎引入了MVCC,其核心目的就是通过空间换时间的方式,实现读写操作的并发执行,极大地提升了数据库的并发处理能力。”“单纯使用锁机制,并发性能会很差。即使是读写锁,读和写操作之间仍然是互斥的。数据库作为高性能中间件,如果一个写操作就导致所有读操作被阻塞,这种性能损失是无法接受的。因此,InnoDB引擎引入了MVCC,其核心目的就是通过空间换时间的方式,实现读写操作的并发执行,极大地提升了数据库的并发处理能力。”更多时候,面试官会直接提问MVCC本身。这时,你可以按照“定义 -> 实现机制 -> 关联隔离级别”的逻辑顺序,简明扼要地回答:“MVCC是MySQL InnoDB引擎用于实现高并发访问的一种协议。它的核心实现主要依赖于两大组件:版本链(Version Chain)和读视图(Read View)。“MVCC是MySQL InnoDB引擎用于实现高并发访问的一种协议。它的核心实现主要依赖于两大组件:版本链(Version Chain)和读视图(Read View)。首先,在InnoDB中,每一行数据都有两个隐藏列:trx_id(最后修改该行的事务ID)和roll_ptr(回滚指针)。通过回滚指针,InnoDB将一行数据的多个历史版本在undo log中串联起来,形成版本链。首先,在InnoDB中,每一行数据都有两个隐藏列:trx_id(最后修改该行的事务ID)和roll_ptr(回滚指针)。通过回滚指针,InnoDB将一行数据的多个历史版本在undo log中串联起来,形成版本链。其次,当一个事务发起快照读时,MVCC会根据该事务的隔离级别(读已提交或可重复读)生成一个Read View。这个Read View定义了一套可见性规则,事务会用这个Read View去匹配版本链,从而找到对当前事务可见的那个特定版本的数据。”其次,当一个事务发起快照读时,MVCC会根据该事务的隔离级别(读已提交或可重复读)生成一个Read View。这个Read View定义了一套可见性规则,事务会用这个Read View去匹配版本链,从而找到对当前事务可见的那个特定版本的数据。”这个回答非常简洁,但覆盖了所有关键点,并且为面试官的追问留下了引子。4.2 亮点方案:推动隔离级别调整这是一个可以充分展示你实践经验和思考深度的亮点。你可以描述你如何推动公司将数据库隔离级别从默认的RR调整为RC。你需要说清楚两点:为什么要把默认的RR降级为RC?降级后,如果真的遇到需要RR特性的场景,该如何处理?为什么要把默认的RR降级为RC?降级后,如果真的遇到需要RR特性的场景,该如何处理?你可以这样组织你的回答:“在我之前参与的一个项目中,我发现我们数据库普遍使用的是MySQL默认的‘可重复读’(RR)隔离级别。但经过深入的业务场景分析后,我发现绝大多数事务并不需要‘可重复读’的特性,比如一个事务内对同一数据的多次读取几乎不存在。“在我之前参与的一个项目中,我发现我们数据库普遍使用的是MySQL默认的‘可重复读’(RR)隔离级别。但经过深入的业务场景分析后,我发现绝大多数事务并不需要‘可重复读’的特性,比如一个事务内对同一数据的多次读取几乎不存在。与此同时,使用RR级别却带来了一些实际问题。首先,RR级别由于临键锁的存在,比RC级别更容易在并发写入时引发间隙锁导致的死锁。我们线上也确实遇到过因此产生的棘手死锁问题。其次,从性能角度看,RC级别下,事务提交后会更快地释放锁,并且undo log的保留链条通常更短,这都意味着RC级别能提供更好的并发性能。与此同时,使用RR级别却带来了一些实际问题。首先,RR级别由于临键锁的存在,比RC级别更容易在并发写入时引发间隙锁导致的死锁。我们线上也确实遇到过因此产生的棘手死锁问题。其次,从性能角度看,RC级别下,事务提交后会更快地释放锁,并且undo log的保留链条通常更短,这都意味着RC级别能提供更好的并发性能。基于这些考虑——业务不需要、存在死锁风险、性能更优——我主导并推动了公司数据库隔离级别的调整,将新业务的默认级别从RR降级为RC,从而提升了系统的整体性能和稳定性。”基于这些考虑——业务不需要、存在死锁风险、性能更优——我主导并推动了公司数据库隔离级别的调整,将新业务的默认级别从RR降级为RC,从而提升了系统的整体性能和稳定性。”此时,面试官很可能会追问:“这个方案很好,但调整之后,如果某个特殊业务确实需要可重复读的特性,你怎么办?”“这是一个非常好的问题,我们在推进时也充分考虑了这一点。我们的解决方案是分层处理:“这是一个非常好的问题,我们在推进时也充分考虑了这一点。我们的解决方案是分层处理:首先,我们会优先尝试从业务逻辑层面进行改造。很多所谓的‘可重复读’需求,其实是可以通过优化代码来满足的。例如,如果一个业务流程中需要多次使用同一份数据,我们完全可以在第一次读取后将结果在应用层面缓存起来(比如放在一个变量里),供后续流程使用,这样就自然避免了对数据库的多次查询。至于幻读,在绝大多数互联网业务中,它通常不被视为一个严重的问题。原因有二:一是业务代码很难区分读到的新数据是幻读,还是在事务开始前就已存在的数据。比如你在事务 A 里面读到了一条数据,你判断不出来它是在事务 A 开始之前就插入的,还是在事务 A 开始之后,事务 B 才插入并且提交的。二是事务的提交通常意味着一笔业务逻辑的完结。如果事务A读到了事务B新插入并已提交的数据,从业务角度看,可以认为事务B所代表的业务已经完成了,那么事务A读到这个“新”结果也是合乎逻辑的。二是事务的提交通常意味着一笔业务逻辑的完结。如果事务A读到了事务B新插入并已提交的数据,从业务角度看,可以认为事务B所代表的业务已经完成了,那么事务A读到这个“新”结果也是合乎逻辑的。当然,如果遇到非常极端、无法通过业务改造来解决的场景,我们还有最后的兜底方案:在代码中为单个事务显式指定隔离级别。我之前调整的是数据库的全局默认隔离级别,但MySQL允许在Session级别,甚至是单个事务级别通过SET TRANSACTION ISOLATION LEVEL REPEATABLE READ;来动态设置隔离级别。这样既能让绝大多数业务享受RC级别带来的整体性能提升,又能以最小的代价灵活应对个别特殊需求,实现了全局最优和局部最优的统一。”当然,如果遇到非常极端、无法通过业务改造来解决的场景,我们还有最后的兜底方案:在代码中为单个事务显式指定隔离级别。我之前调整的是数据库的全局默认隔离级别,但MySQL允许在Session级别,甚至是单个事务级别通过SET TRANSACTION ISOLATION LEVEL REPEATABLE READ;来动态设置隔离级别。这样既能让绝大多数业务享受RC级别带来的整体性能提升,又能以最小的代价灵活应对个别特殊需求,实现了全局最优和局部最优的统一。”回到开篇:既然有锁,为什么还要引入 MVCC?答案就在于 MVCC 用版本链 + ReadView把读写解耦了。在保证必要隔离的同时大幅提升并发读取性能。锁解决的是谁能改的问题,而 MVCC 解决的是该读谁的数据、在什么时候读的问题。它以版本链和可见性规则,让每个事务都能在自己的时间线里安全读取数据,不必被锁束缚。正因为有了 MVCC,MySQL 才真正实现了读写并行,在一致性与性能之间取得平衡。它不是为了取代锁,而是弥补锁的局限,让数据库在高并发的世界里依然保持秩序与速度——这正是 MVCC 存在的意义,也是事务并发控制的灵魂所在返回搜狐,查看更多
-
还是打不过?为什么Uber要从Postgres迁移到MySQL? Postgres 和 MySQL 有什么区别?简单来说,这两种数据库的核心差异,主要体现在主键索引和二级索引的实现方式,以及底层的数据存储与更新机制上。接下来,我们就来详细看看这两者的不同之处。一、索引索引是一种用于加速查询的数据结构,通常采用 B+ 树实现。这种结构通过多层节点进行键值查找,数据库内部通常以“页(page)”的形式组织这些节点。查找过程中,系统会从根节点出发,逐层遍历树结构,逐步排除不包含目标数据的页面,直到最终定位到包含目标键的叶子页面。叶子节点中存储的是有序的键(key)以及对应的值(value)。一旦定位到目标键,便可直接获取相应的值。与此同时,该页面会被缓存在数据库的共享缓冲区中,以便后续查询可以重用,从而提升查询效率。在 B+ 树索引中,“键”指的是创建索引时指定的列,而“值”是什么,不同的数据库有不同的实现方式。接下来,我们就来看看 Postgres 和 MySQL 在这方面的具体差异。1、MySQL在 MySQL 中,主键索引的“值”其实就是整行数据本身,即该行的所有字段内容。这也是为什么主键索引通常被称为“聚簇索引”。需要说明的是,这里的描述是基于行存储的数据库系统。对于采用列存储、图数据库或文档型数据库的系统来说,由于存储模型不同,“值”的定义也会有所区别。当通过主键索引查找某个键对应的数据时,只需定位到该键所在的页面,就可以直接获取整行数据,无需额外的 I/O 操作去读取其他列,因为其值包含了整行数据本身。而在二级索引中,键是你创建索引时指定的列,但“值”不再是整行数据,而是一个指针,用于定位这条完整数据所在的位置。通常来说,二级索引叶子节点中的值就是对应行的主键值。展开全文也正因如此,MySQL 要求每张表必须有一个主键索引,所有二级索引最终都要通过主键来定位数据。如果没有显式定义主键,MySQL 会自动为你生成一个隐藏主键。2、Postgres在 Postgres 中,从技术上讲并没有“主键索引”的概念,所有索引本质上都是二级索引。它们都指向系统管理的 tuple ID(元组 ID),根据这些 ID 再定位到实际存储在堆中的数据页。需要注意的是,堆中的表数据是无序的,并不像聚簇索引的叶子节点那样按键值顺序排列。举个例子,如果你依次插入第 1 到第 100 行数据,这些行可能会被存储在同一个页面中;但如果你随后更新了第 1 到第 20 行,这些更新后的数据很可能会被写入到其他页面,从而导致数据的物理分布变得无序。而在 MySQL 的聚簇索引中,插入操作需要保证数据按键值(也就是索引字段值)顺序写入,这就限制了数据的物理排列方式。因此,Postgres 中的表通常被称为“堆组织表(heap organized tables)”,而不是“索引组织表(index organized tables)”。此外需要特别注意的是,在 Postgres 中,更新和删除操作本质上其实都是插入操作。每次执行更新或删除时,系统都会生成一个新的元组 ID(tuple ID),而原有的元组 ID 会被保留下来,用于支持 MVCC(多版本并发控制)机制。这个细节我们稍后会在文章中进一步探讨。实际上,仅有元组 ID 并不足以定位具体数据,还需要知道该元组所在的数据页编号。这两个信息组合在一起,称为 c_tid。想一想,如果只有元组 ID 而不知道它在哪一页,是无法直接定位数据的。由于在 Postgres 中,索引只保存元组的位置信息,因此必须多执行一次 I/O 操作来加载对应的数据页,才能获取完整的行数据。二、查询代价我们来看下面这张示例表:# 表 T;# 主键列 PK 上有主索引,C2 列上有二级索引,C1 没有索引;# C1 和 C2 是文本类型,PK 是整数。PK | C1 | C2 |----|----|----|1 | x1 | x2 |2 | y1 | y2 |3 | z1 | z1 |现在,我们对比在 MySQL 和 Postgres 中执行以下 SQL 查询时的差异:SELECT * FROM T WHERE C2 = x2;在 MySQL 中,这条查询会涉及两次 B+ 树查找操作。首先,通过 C2 列的二级索引查找字段 C2 值为 x2 的记录,获取其对应的主键值 1;接着再通过主键索引查找主键为 1 的那一行数据,从而获取整行记录( * 表示所有的字段)。有些人可能会认为,这只是两次 I/O 操作,其实并非如此。B+ 树查找的时间复杂度是 O(logN),当索引规模较大时,一次查找可能涉及多个节点,每个节点对应一个页面,因此可能触发多次 I/O 操作。而在 Postgres 中,执行这条查询时,首先通过 C2 列的二级索引查找匹配的元组 ID,然后进行一次堆访问,从堆中加载包含完整行数据的页面。从访问路径来看,大多数情况下,一次索引查找加一次堆访问要比两次 B+ 树查找更高效,也就是说,Postgres 在这种场景下的查询性能往往优于 MySQL。为了让这个例子更贴近实际,我们进一步假设:C2 列的值并不唯一,也就是说,可能有多行记录的 C2 值都是 x2。在这种情况下,查询过程中会返回多个匹配的元组 ID(在 MySQL 中则是多个主键值)。问题在于,这些匹配的行可能分布在多个不同的数据页上,导致大量随机读操作。在 MySQL 中,这意味着要重复进行多次主键索引查找(当然,查询优化器也可能根据匹配记录数量,选择走索引扫描而非逐条查找),但无论是在 MySQL 还是 Postgres 中,这种情况最终都不可避免地带来频繁的随机 I/O。为尽量减少这种随机访问,Postgres 会采用位图索引扫描(Bitmap Index Scan) 的方式来优化查询流程:首先将所有匹配结果按照页面而非单条元组进行聚合,然后一次性批量加载这些数据页,尽可能降低 I/O 次数。接下来再在内存中进行过滤,最终返回满足条件的记录。接下来,我们来看一个查询的例子。SELECT * FROM T WHERE PK BETWEEN 1 AND 3;在主键索引上的范围查询方面,MySQL 的表现更为出色。它只需进行一次查找,定位到第一个匹配的键,然后沿着 B+ 树叶子节点的链表依次向后遍历,获取相邻的键,并在遍历过程中直接读取对应的整行数据。相比之下,Postgres 在这方面就显得吃力一些。虽然它的二级索引同样会在 B+ 树的叶子节点上进行遍历,找到所有匹配的键,但它只会收集对应的元组 ID 和页面信息,但此时工作并未就此完成。Postgres 还需要执行额外的随机读操作,从堆中加载这些元组对应的完整行数据。而这些数据行很可能分布在堆的不同位置,尤其是在频繁更新的情况下,数据往往不会连续、紧凑地存放在一起。对于更新频繁的场景来说,这正是 Postgres 的一项劣势。因此,为表设置合适的 FillFactor(填充因子)非常重要,它可以在一定程度上可以缓解数据分散带来的性能问题。接着,我们来看一个更新操作的例子:UPDATE T SET C1 = XX1 WHERE PK = 1;在 MySQL 中,如果更新的是一个未被索引的列,那么只需在主键索引的叶子节点中,直接修改该行对应的字段值即可。由于所有的二级索引都通过主键进行定位,而主键值本身没有发生变化,因此不需要更新任何索引结构。而在 Postgres 中,即使更新的是一个没有索引的列,系统也会生成一个新的元组并赋予新的元组 ID,这意味着,所有原本指向旧元组的二级索引项都需要更新为指向新元组的位置。换句话说,虽然索引列本身并未发生变化,但由于底层的元组位置发生了改变,相关索引也“可能”需要更新,从而引发大量的写入 I/O。早在 2016 年,Uber 就曾明确表达过对这一机制的不满,这也是他们将数据库从 Postgres 迁移到 MySQL 的主要原因之一。这里之所以说“可能”需要更新所有二级索引,是因为 Postgres 中存在一个名为 HOT(Heap Only Tuple)的优化机制。这个优化的原理是:在满足一定条件的情况下,允许二级索引保留原有的元组 ID,而不立即更新为新生成的元组 ID。此时,Postgres 会在堆页面内,通过在旧元组和新元组之间建立一个链表,从旧元组跳转到新元组,实现不同版本之间的关联。这样就可以避免更新索引,从而减少写入 I/O 的开销。三、数据类型很重要在 MySQL 中,主键的数据类型至关重要,因为所有二级索引都需要存储对应的主键信息。举例来说,如果主键使用的是 UUID,那么每条二级索引记录中都要包含这个较长的主键值,导致二级索引变得臃肿,不仅占用更多的存储空间,也会带来更高的读 I/O 开销。而在 Postgres 中,二级索引并不存储主键的实际值,而是统一使用固定大小为 4 字节的元组 ID(tid)来指向堆中的数据。正因如此,即使主键是 UUID,二级索引的大小也不会受到影响。四、撤销日志(Undo Logs)几乎所有现代数据库都支持多版本并发控制(MVCC)。以最常见的“已读提交”(Read Committed)隔离级别为例,如果一个事务 tx1 对某一行数据进行了更新但尚未提交,而此时另一个并发事务 tx2 试图读取这行数据,那么它应当读取更新前的旧值,而不是尚未提交的新值。大多数数据库(包括 MySQL)通过撤销日志(Undo Logs)来实现这一机制。当某个事务修改了一行数据时,变更会直接写入共享缓冲池中的页面,也就是说,该页面始终保存的是最新的数据。随后,事务会将“如何撤销这次变更”的信息写入撤销日志(Undo Log),以便在需要时可以还原该行数据的旧状态。这样,当并发事务基于自身的隔离级别需要读取旧版本数据时,系统就可以通过解析 Undo Log 构造出对应的旧数据行。你可能会疑惑:将未提交的修改直接写入页面,真的安全吗?如果后台进程把这个页面刷入磁盘,而事务还没提交,此时数据库突然崩溃了怎么办?这正是Undo Log存在的意义。在数据库启动时,如果检测到之前发生了崩溃,会在恢复阶段利用 Undo Log 回滚那些未提交的变更,从而确保数据一致性不被破坏。当然,Undo Log 会对并发事务带来额外的开销,尤其是在存在长事务的情况下。为了构造旧版本数据,系统需要执行额外的 I/O 操作,而且Undo Log 也有可能被写满,从而导致事务失败。我曾遇到过一个真实案例:某数据库系统在崩溃恢复时,光是回滚一个运行了 3 小时但未提交的长事务,,就耗费了一个多小时。由此可见,尽量避免长事务,是非常有必要的。而 Postgres 的处理方式则完全不同。每一次更新、插入或删除操作,都会生成该行数据的一个新副本,并分配一个新的元组 ID(tuple ID),同时记录创建和删除该元组的事务 ID。借助这些信息,Postgres 可以安全地将变更写入数据页,并允许并发事务根据自身的事务 ID 判断应读取旧版本还是新版本的数据。这个设计非常巧妙。当然,再巧妙的方案也并非没有代价。我们之前就提到过,为每次变更生成新的元组 ID,会对二级索引带来额外开销。此外,Postgres 还需要在适当时机清理那些不再需要的旧元组,这项清理工作则由 Vacuum 机制负责执行。五、Processes vs ThreadsMySQL 使用的是线程模型,而 Postgres 则采用的是进程模型。两者各有优劣,我在另一篇文章中已做过详细分析。就个人而言,在数据库系统中,我更倾向于使用线程。原因很简单,线程更轻量,而且能共享父进程的虚拟内存地址空间。而进程则需要独立的虚拟内存,其进程控制块(PCB)也比线程控制块(TCB)更大,资源开销更高。作者丨上善若水来源丨公众号:码农有道(ID:b497155298)dbaplus社群欢迎广大技术人员投稿,投稿邮箱:editor@dbaplus.cn返回搜狐,查看更多
-
Oracle 翻车之作:MySQL Cluster 的失败根源与设计原罪 大家是否记得 Oracle的一个数据库产品 MySQL中的一个项目 NDB,说这个可能还有人想不起来,MySQL Cluster,想起来了吧。曾经MySQL推出的一个MySQL的高可用模式,MySQL Cluster. 为什么说这是一个失败的产品,因为这个产品在以下几个地方,有一些值得人思考的问题。产品设计混乱,如果ORACLE有 RAC,Oracle Real Applicaiton Clusters,那么这个产品就是再此概念上做出来的 MySQL也应该有一个和Oracle 一样的高可用产品的思路。可我特别想问几个问题,如果ORACLE 有RAC ,那么客户关注的事什么,用MySQL的客户为什么也要关心这个事情。ORACLE 的客户画像是什么,ORACLE的产品经理,应该有这个分析和报告。那么按照ORACLE的客户画像来,翻印的MySQL客户也有这个需求,是从何而来的这个结论。Oracle RAC 是一种“共享一切”的数据库集群架构。它由两个或多个计算机构成一个集群,这些计算机(节点)通过高速网络(Interconnect)连接,并共享同一组磁盘存储(Shared Storage)。MySQL的NDB,一个类似Oracle 的RAC的东西,最初是为电信计费设计的,他强调的事毫秒响应时间,高可用以及分布式冗余,并且要求再此上的事务高度结构化,且短事务。此时不禁要问一句,ORACLE 你已经有了ORACLE这样的数据库巨无霸,而搞出MySQL NDB的缘由是什么。NDB的核心设计是在分片和shared nothing的架构上,数据分布在多个节点,对于主键的查询速度非常快,而只要涉及到普通数据库的 join, group by 等就马上不行了。同时ORACLE在NDB上进行了一些努力,但是基于分布式的概念在0RACLE天生的缺陷,如设计了协调器而数据的性能大量损耗在网络通信和数据传输中。同时基于NDB非常不擅长复杂查询的特性,虽然也研究了下推的方式减少网络和节点传输数据,但存在JOIN的列的类型限制等诸多问题。同时一些自身的ORACLE的专家,还试图给ORACLE刷白,我们来看这段。But the way MySQL Cluster splits data in a sharded manner over the data node pairs means that it supports queries best if they are lookups for specific rows by their primary key. Range queries likely have to span many data nodes. Join queries also have to span many data nodes. Complex reporting queries have terrible performance.展开全文Many people who dont understand this tradeoff attempt to port their existing application to use MySQL Cluster, and are disappointed in the performance. It may give no improvement over using InnoDB, or it can even show a drop in performance.This isnt a weakness of MySQL Cluster -- its a weakness of a physically sharded architecture in general.但是 MySQL Cluster 在数据节点对上以分片方式分割数据的方式意味着,如果查询是通过主键查找特定行,它最支持查询。范围查询可能必须跨越许多数据节点。连接查询也必须跨越许多数据节点。复杂的报告查询性能很差。 许多不理解这种权衡的人试图将他们现有的应用程序移植到使用 MySQL 集群,并对性能感到失望。它可能不会比使用 InnoDB 有任何改进,甚至会显示性能下降。 这不是 MySQL Cluster 的弱点 —— 这是一般物理分片架构的弱点。这上面这位仁兄的解释是,不支持复杂查询不是MySQL Cluster的弱点,而是分片结构的弱点。继续辩解为mysql cluster硬件预算。您需要大量服务器,而每台服务器都需要大量 RAM。您可能还需要将集群放在专用子网上,并为您的所有主机购买高端 NIC。软件是免费的,但基础设施和操作可能很昂贵。 配置和调优知识。NDB 不是 MySQL 站点中最常用的存储引擎 InnoDB。所以很多调优智慧和留档并不适用。找到能够有效操作 MySQL 集群站点的 DBA 很难。或者你可以从一个有主流 MySQL 知识的称职 DBA 开始,给他们时间来培训 NDB,但这也既耗时又昂贵。 模式设计。任何分片架构都需要有一个旨在利用分片的模式。如果查询只触及一个分片,查询效果很好。但有时您还需要运行一个范围查询,该查询将触及所有分片。我的雇主Percona为几家公司提供咨询,他们阅读了 MySQL 集群的高基准数字,因此他们简单地将现有应用程序导入 MySQL 集群实例,发现它比使用传统 MySQL 实例时性能更差。上面一些国外数据库专家为MySQL Cluster的辩解,让我们可以窥见更多的MySQL Cluster的缺陷。总结为:需要大内存,以及更多的主机,因为数据全部要在内存中处理数据的格式和数据的操作方式,并不和MySQL完全兼容之前在MySQL可以很好解决的一般复杂SQL查询的问题,在NDB集群并不能很好的解决现有的应用程序,如果构建在MySQL上,是无法安全的且完全的移植到应该主键查询,且对于范围查询十分的不友好MySQL Cluster 文档而官方的我找到的MYSQL CLUSTER的文档,对于以上问题,一概不谈,都是围绕数据库的高可用去谈论数据库产品的,对于数据查询的难点,和应用的改造只字不提。后来查了一下这个系统的历史,这个系统并不是Oracle自研的,而是收购Ericsson 而来了,而当初这个系统的产生完全是针对电信行业特定的系统而生,并不是为了广泛的数据库应用而设定的。Ericsson所以从上述的信息收集和信息的分析,MySQL Cluster本身就不是为了广泛的数据库客户服务的,他出自瑞典爱立信的内部的数据库系统。爱立信最后根据网络查询的NDB的问题点总结如下:核心是同步内存分布式架构,shared Nothing In Memory数据节点全部内存驻留,虽然后期支持磁盘,但是性能会急剧下降所有更新操作都需要两阶段在多个节点提交完成,节点数量变大将导致写放大,和网络数据同步的消耗变大无法完成JOIN 的数据查询,导致数据库无法完成普通数据库可以完成的任务,官方建议使用 KEY VALUE进行数据的提取和存储。系统没有分布式性能优化器,仅仅支持 RC的隔离级别对于MYSQL 本身支持的功能不支持,全文索引,空间索引,约束,外键,触发器,存储过程,等管理极其复杂,包含了 NDB_MGMD , NDBD ,MYSQLD 等组件配置极其复杂对于系统启动顺序要求非常敏感写到这里,让我想起另一个数据库的类似杰作,POSTGRESQL XL XC系统。另外一些论坛中对于NDB系统的有一个用户的评价,就怕出问题,出了问题,一修就是半天。综上所述,MySQL CLUSTER 系统是一个ORACLE 在自己数据库产品中失败的杰作,收购,且针对极为特殊的业务场景,与当前的大部分数据库系统相比,无法完成基本的JOIN SQL查询的工作,系统扩展后,并不能得到系统的性能提升,种种问题。NDB 测试场景(顺便说一句,ORACLE在官方文档开始淡化 NDB CLUSTER)作者介绍刘华阳,20年经历风霜雨打的 DBA,5年的 DBA 架构和团队管理经验,只要是数据库都喜欢学习。PostgreSQL ACE,MongoDB 狂热者,10年的 MYSQL 工作经验,现在在玩 POLARDB 与时俱进。来源丨公众号:AustinDatabases(ID:AustinDatabases)dbaplus社群欢迎广大技术人员投稿,投稿邮箱:editor@dbaplus.cn返回搜狐,查看更多